|
|
В процессе переноса алгоритма распознавания маркеров на OMAP платформу я обнаружил, что начисто забыл каким образом высчитывается память, которая распределяется между ARM и DSP. Восстанавливая крупицы ценной информации, которые щедро разбросаны по разным мануалам и форумам Texas Instruments, я решил зафиксировать с таким трудом добытые и упакованные в некоторое подобие осмысленной системы данные.
Мы будем пользоваться услугами Codec Engine от TI, про эту систему обеспечения передачи данных между ARM и DSP я немного рассказал в другой статье. Там же я упомянул, что CE берет на себя заботу о выделении необходимой нам памяти, поэтому самое время рассказать о том как это делается.
Как вы понимаете, в архитектуре OMAP подсистемы ARM и DSP работают с общей памятью. Поэтому придется учитывать их требования и интересы чтобы избежать конфликтов; более того, они совместно используют разделяемую память для обмена. Ситуацию усугубляет то, что ARM Linux работает с виртуальной памятью, а DSP — с физической — читает и пишет как есть, по реальным адресам.
На самом деле, нам нужно организовать три типа памяти:
- которая нужна только ARM;
- которая нужна только DSP;
- разделяемая память, через которую ARM и DSP обмениваются данными (с любезной помощью Codec Engine).
Поехали.
ARM only
С ARM все обстоит проще всего. Здесь крутится Linux со своей системой виртуальной памяти, который самостоятельно назначает адреса из виртуального пространства. Как мы помним, в концепции виртуальной памяти ее может быть даже больше, чем количество физической. Нам нужно сделать только одну вещь — ограничить аппетиты Linux, а точнее обмануть его насчет физической памяти, доступной в системе. На моей плате BeagleBoard расположено ОЗУ емкостью 512МБ. Не мудрствуя лукаво, отдадим Linux половину.
Делается это в конфигурации загрузчика, который во время загрузки ядра передает последнему командную строку следующего вида:
|
|
Kernel command line: console=ttyO2,115200n8 mem=256M omapfb.vram=0:3M omap_vout.vid1_static_vrf b_alloc=y ethaddr=00:02:03:aa:bb:01 mpurate=auto buddy=none camera=none vram=16M omapfb.mode=dvi:640x48-24@60 omapdss.def_disp=dvi root=/dev/mmcblk0p2 rw rootfstype=ext3 rootwait |
Нас интересует параметр mem=256M, который указывает Linux на какой объем памяти он может рассчитывать. Сразу заметим, что из этой памяти 256М параметр vram=16M заберет 16 мегабайт: это размер видеопамяти для фреймбуфера. Кстати, вот еще один провал в памяти: эти строки, совместно с omapfb.vram=0:3M, omapfb.mode=dvi:640×48-24@60, omapdss.def_disp=dvi я настраивал для отображения видео через dvi и точно помню, что рассчитывал размер картинки отдельно для каждого из цветов RGB. Для того, чтобы сказать почему фреймбуферу нужно отдать именно 16 мегабайт, мне нужно будет погрузиться в аналогичные воспоминания )
После загрузки с такой командной строкой ядро отрапортует:
|
|
Memory: 240MB = 240MB total |
Все правильно, это доступная память 256М за вычетом видеопамяти 16М. Проверяем:
|
|
# free -h total used free shared buff/cache available Mem: 224M 54M 122M 356K 48M 158M Swap: 0B 0B 0B |
Опс… почему 224М? А потому что ядру тоже нужно место, и если мы посчитаем сколько оно занимает, в сумме получится 16М:
|
|
[ 0.000000] Virtual kernel memory layout: [ 0.000000] vector : 0xffff0000 - 0xffff1000 ( 4 kB) [ 0.000000] fixmap : 0xfff00000 - 0xfffe0000 ( 896 kB) [ 0.000000] DMA : 0xffc00000 - 0xffe00000 ( 2 MB) [ 0.000000] vmalloc : 0xd0800000 - 0xf8000000 ( 632 MB) [ 0.000000] lowmem : 0xc0000000 - 0xd0000000 ( 256 MB) [ 0.000000] modules : 0xbf000000 - 0xc0000000 ( 16 MB) [ 0.000000] .init : 0xc0008000 - 0xc0039000 ( 196 kB) [ 0.000000] .text : 0xc0039000 - 0xc0671334 (6369 kB) [ 0.000000] .data : 0xc0672000 - 0xc083ca40 (1835 kB) [ 0.000000] .bss : 0xc083ca64 - 0xc0dd2888 (5720 kB) |
Итак, из доступной на BeagleBoard памяти 512М мы отдали Linux 256М и 256М осталось для DSP и Codec Engine. В самом Linux эти 256М разошлись так: на видеопамять 16М, на ядро тоже 16М, в результате приложениям осталось 224М. Теперь смотрим дальше, что будет происходить с оставшимся объемом 256М.
DSP only
Как я уже упомянул, DSP оперирует физическими адресами в памяти. Поэтому нам нужно вооружиться шестнадцатеричным калькулятором и составить таблицу распределения памяти. Мы начнем с адреса 0x80000000, потому что начиная с него начинает стартовать шина памяти. Запомним полезное число: 0x10000000, которое соответствует размеру памяти 256М, которую мы отдали ARM. Это означает, что доступная для дальнейших экспериментов (то, что осталось после того как Linux забрал свое) область будет начинаться с 0x80000000 + 256М = 0x90000000.
Как вы уже догадались, с диапазоном адресов от 0x80000000 до 0x90000000 будет работать Linux.
Теперь нам нужно принять важное решение: какую часть из оставшейся памяти отдать DSP? На несвоевременный вопрос «почему не всю оставшуюся»? отвечаю, что нам еще нужно распределить область обмена между ARM и DSP. Об этом будет в третьем параграфе, а сейчас мы договоримся, что отдаем DSP область 0x90C00000 — 0xA0000000.
С концом памяти все понятно: это 0x80000000 + 512М, то есть конец физической памяти. Откуда взялось значение 0x90C00000? Отвечу на это, что как и все важные решения, оно было принято «отфонарным» способом. Ладно, шучу, шучу ) Почему именно такая граница, я покажу опять таки в следующем параграфе. А сейчас мы посмотрим, каким образом приложение на DSP стороне узнает о наших важных решениях.
Делается это с помощью конфигрурационного файла config.bld, интересуемый кусок которого в нашем случае будет выглядеть следующим образом:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
var evm3530_ExtMemMap = { DDRALGHEAP: { name: "DDRALGHEAP", base: 0x90C00000, len: 0x03000000, space: "data" }, DDR2: { name: "DDR2", base: 0x93C00000, len: 0x03000000, space: "code/data" }, SR1: { name: "SR1", base: 0x96C00000, len: 0x00200000, space: "data" }, SR0: { name: "SR0", base: 0x96E00000, len: 0x00200000, space: "data" } }; |
Как следует из записи, DSP использует еще более тонкую нарезку памяти для различных нужд, например DDRALGHEAP это память предназначенная для самого Codec Engine. Мы не будем сильно погружаться в эту структуру, для нас существенным является то, что для DSP будет выделена память начиная с адреса 0x90C00000 и завершит эту область сегмент SR0 (Shared Region). Поскольку сегменты идут непрерывно друг за другом (сумма базы сегмента и его длины равна базе следующего сегмента), то последний занятый адрес памяти будет 0x96E00000 + 0x00200000 = 0x97A00000.
Вот мы и определили область памяти, с которой будет работать DSP. Она начинается с физического адреса 0x90C00000 и заканчивается физическим адресом 0x97A00000. В самом коде нет необходимости помнить о физических границах. В частности, механизм Codec Engine самостоятельно выделяет память для массивов данных в этих границах, для этого он вызывает функцию следующего вида, в которой только нужно заполнить структуру memTab и указать, сколько памяти и с какими характеристиками нам нужно:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
Int LW_AF_alloc(const IALG_Params *algParams, IALG_Fxns **pf, IALG_MemRec memTab[]) { /* Request memory for my object */ memTab[0].size = sizeof(LW_AF_Obj); memTab[0].alignment = 0; memTab[0].space = IALG_EXTERNAL; memTab[0].attrs = IALG_PERSIST; /* Request memory for twiddle buf */ memTab[1].size = BUFSIZE_1D; memTab[1].alignment = 8; memTab[1].space = IALG_EXTERNAL; memTab[1].attrs = IALG_PERSIST; * * * /* Request memory for img tmp buf */ memTab[6].size = BUFSIZE_2D; memTab[6].alignment = 8; memTab[6].space = IALG_EXTERNAL; memTab[6].attrs = IALG_PERSIST; return(NUMBUFS); } |
После выделения памяти, кодек отдаст нам указатели на выделенные области памяти в memtab[0].base … memtab[6].base.
ARM + DSP
Здесь начинается самое интересное. Нам нужен разделяемый массив памяти, который одновременно будет использовать как ARM, так и DSP. Через этот массив Codec Engine будет гнать данные в обеих направлениях.
Управляет распределением модуль ядра CMEM, который запускается со стороны ARM Linux. Модуль принимает параметры, через которые задаются размеры и местонахождения пулов памяти. Выглядит это примерно так:
|
|
MODPATH=/lib/modules/3.0.50/kernel/drivers/dsp/ # start syslink and cmem insmod $MODPATH/syslink.ko TRACE=1 TRACEFAILURE=1 # BeagleBoard mem=256M version insmod $MODPATH/cmemk.ko phys_start=0x90000000 phys_end=0x90C00000 pools=20x4096,10x131072,4x2621440 |
Перед запуском модуля cmemk.ko запускается собственно модуль syslink.ko, принадлежащий Codec Engine.
Из конфигурации CMEM видно, что используется область памяти от 0x90000000 до 0x90С00000, и это логично, потому что после 0x90С00000 идет уже область памяти эксклюзивно принадлежащая DSP. И все таки, откуда взялось это значение — 0x90С00000? Чтобы ответить на этот вопрос, обратим внимание на распределение пулов памяти, заданное параметром pools. Для моего проекта самым важным является передача сигнального и опорного 2D изображения с ARM на DSP, а также передача результата — 2D изображения в обратном направлении. Одна матрица остается в запасе, поэтому я распределил 4 пула размером 2621400 байт. В этот размер поместится байтовая черно-белая картинка размером 1280х1024 комплексных чисел.
Замечу, что поскольку CMEM — менеджер непрерывной памяти, то использовать пул кусками не получится. То есть нельзя будет в области размером 2621400 байт взять например два массива половинной длины. Один массив — один пул, такое правило. Я взял 4 пула чтобы иметь запас для матриц изображения, а для данных поменьше распределил 10 пулов по 131024 байт и 20 пулов по 4096 байт. Считаем границы:
0x96E00000 + 20 х 4096 + 10 х 131024 + 4 х 22621400 = 0x90С00000. Вот откуда взялось это значение.
Со стороны Linux указатели на эти области памяти возвращаются функциями вида
inBufSigImgArm = Memory_alloc(BUFSIZE_2D, &allocParams);
После этого указатели прописываются в специальной структуре, которая волшебным образом, с помощью Codec Engine также будет доступна со стороны DSP:
ARM:
|
|
universalInBufDesc.descs[0].bufSize = BUFSIZE_1D; universalInBufDesc.descs[1].bufSize = BUFSIZE_1D; universalOutBufDesc.descs[0].bufSize = BUFSIZE_1D; // указатели попадают в структуру universalInBufDesc.descs[0].buf = inBufSigImgArm; universalInBufDesc.descs[1].buf = inBufRefImgArm; universalOutBufDesc.descs[0].buf = outBufImgArm; |
DSP:
|
|
inBufSigImgDsp = inBufs->descs[0].buf; inBufRefImgDsp = inBufs->descs[1].buf; outBufImgDsp = outBufs->descs[0].buf; |
Вот и все. Если структура имеет тип In, то данные заполненные со стороны ARM, после вызова кодека со стороны ARM попадут в функцию, которая будет вызвана со стороны DSP. И наоборот, результат работы DSP, который в структуре имеет тип Out, будет возвращен в ARM.
В моем проекте DSP выполняет тяжелонагруженные процедуры вычисления свертки изображений, которые требуют двумерного преобразования Фурье. Конечно, целочисленная арифметика DSP в архитектуре OMAP это не совсем то, что нужно для такого проекта. Но попробовать стоило, хотя бы для того чтобы сравнить быстродействие с другой реализацией — двумерное преобразование Фурье на GPU Raspberry Pi. Об этом — в следующих материалах
Блокчейн используется не только в криптовалютах, а также в тех областях где нужно сопровождать доказанную последовательность определенных событий или состояний. Об этом буквально и говорит само слово blockchain: цепочка блоков. Таким образом, с системной точки зрения мы имеем блоки и связи между ними. Наша задача — препарировать блок таким образом, чтобы установить наличие данной связи (проверка блокчейна). Или создать новую связь — это уже майнинг, слово приводящее в трепет публику которая вращается в мире криптовалют.
Поработаем с блоками и связями такой популярной криптовалюты, как BitCoin.
Блоки и связи / Block & Chains
Типичный блок выглядит следующим образом:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "hash":"0000000000000bae09a7a393a8acded75aa67e46cb81f7acaa5ad94f9eacd103", "ver":1, "prev_block":"00000000000007d0f98d9edca880a6c124e25095712df8952e0439ac7409738a", "mrkl_root":"935aa0ed2e29a4b81e0c995c39e06995ecce7ddbebb26ed32d550a72e8200bf5", "time":1322131230, "bits":437129626, "nonce":2964215930, "n_tx":22, "size":9195, "block_index":818044, "main_chain":true, "height":154595, "received_time":1322131301, "relayed_by":"108.60.208.156", "tx":[--Array of Transactions--] { |
Блоки хорошо представлять в виде вагончиков, которые сцепляются друг с другом. Эта аналогия обладает еще одним ценным соответствием: самый первый вагончик, то есть паровозик, не сцеплен спереди ни с кем. Это самый верхний блок в системе, и он будет самым верхним до тех пор, пока кто-нибудь не намайнит следующий блок. Тогда новый блок становится паровозиком во главе состава и к нему подцепляется остальная цепочка.
Все! В блокчейне больше ничего нет, кроме сцепленных вагончиков — блоков. Теперь нужно понять, что выполняет роль этой сцепки. Вот тут в этом месте наше сравнение с вагончиками не сработает, потому что в пассажирском или грузовом составе каждый вагон может быть сцеплен с любым другим вагоном или локомотивом, а в случае блокчейна для того чтобы вагончики сцепились, их сцепной механизм должен иметь одинаковый код.
В блоках роль этого кода выполняют значения ключей hash и prev_block. В блокчейне значение prev_block каждого блока в точности совпадает со значением hash предыдущего блока, и аналогично hash каждого блока совпадает со значением prev_block последующего блока. При этом при вычислении значения hash используется хэш предыдущего блока, что делает цепочку хешей зависимой друг от друга.
Поскольку hash — это фактически хэш блока, то такой механизм обеспечивает не только однозначность последовательности блоков, но и защиту содержимого блока. Попытка изменить последовательность блоков, удалить блоки или вставить новые, а также поменять содержимое самих блоков ни к чему не приведет: нарушится соответствие последовательности хэшей. Поэтому с блокчейном ничего сделать нелья: можно только добавить новый блок спереди. Это уже майнинг!
Block Parsing
Распарсим один из блоков блокчейна. Я взял для примера блок #528340, хэш которого имеет значение
0000000000000000002740c2167e7dcea59e11362587ea9ed348022701f5a73d.
Вы наверное обратили внимание на то, что хэши имеют вначале большое количество нулей, что вообще-то говоря очень странно для хэш-функции, которая должна выглядеть как стопроцентно случайная последовательность. В этом и есть соль майнинга: блок получает право возглавить блокчейн только в том случае, если его хеш будет иметь в начале определенное количество нулей. В этом и заключается вычислительная трудность, на которую тратят время майнеры.
Заканчиваем с лирическими отступлениями и приступаем к парсингу. Блок будем брать прямо с сайта по его хэшу:
|
|
# block #528340 hash block_hash = '0000000000000000002740c2167e7dcea59e11362587ea9ed348022701f5a73d' url = 'https://blockchain.info/rawblock/%s' r = requests.get(url % block_hash) print(r.status_code) data = json.loads(r.text) |
Если код статуса равен 200, значит на запрос получен ответ с нужными данными в формате JSON, которые преобразуются в словарь с парами ключ — значение (переменная data).
Поскольку изобретатели алгоритма решили работать с данными справа налево, в режиме реверса последовательности байтов в строке, я написал вспомогательную функцию которая это делает:
|
|
def sformat(data, arg): s = data[arg] l = list(s) i=0 for ch in reversed(s): if i%2 != 0: l[i-1]=ch l[i]=ch0 else: ch0=ch i+=1 ret = ''.join(l) print('%s: %s' % (arg,ret)) return(ret) |
Переформатируем все переменные, которые будут принимать участие в вычислении хэша:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
bl=sformat(data, 'hash') pb=sformat(data, 'prev_block') mr=sformat(data, 'mrkl_root') # new dict to unify call function sformat() data2 = {'ver':'','time':'','bits':'','nonce':''} data2['ver']='%x' % data['ver'] ve=sformat(data2, 'ver') data2['time']='%x' % data['time'] ti=sformat(data2, 'time') data2['bits']='%x' % data['bits'] bi=sformat(data2, 'bits') data2['nonce']='%x' % data['nonce'] no=sformat(data2, 'nonce') |
Теперь все это нужно смешать в одну кучу
и найти значение хэша нашего блока:
|
|
header_bin = header.decode('hex') pass1=sha256(header_bin).digest() new_block=sha256(pass1).digest()[::-1].encode('hex') |
Не забываем, что в этой операции участвовал хэш предыдущего блока prev_block. В результате получаем заветную строчку со многими нулями вначале — это и есть хэш нашего блока, все соответствует.
Полезная нагрузка: транзакции
За повествованием мы забыли про полезное наполнение блока, ради чего все собственно затевалось: про транзацкции, кто кому сколько перечислил. Транзакций в блоке великое множество, они проходят под ключом tx. Gосмотрим только одну из, например самую верхнюю n=0:
|
|
print(json.dumps(data['tx'][n], ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ': '))) |
Информацию дает строчка json.dumps(data[‘tx’][n]), остальное — красивости для удобочитаемого вывода. В результате увидим:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
{ "hash": "eaa674093137d79c025f2a86660c25af3c9ba492542c0f92daa5b58c1e5a15b9", "inputs": [ { "script": "03d40f08046d1b2a5b2f4254504f4f4c2ffabe6d6d4a6c034e5c60e2b4ff7ae75f8a2160ece386d768b82cf03f745694e8b2a911d9010000000000000002019a460996010000000000", "sequence": 4294967295, "witness": "01200000000000000000000000000000000000000000000000000000000000000000" } ], "lock_time": 0, "out": [ { "addr": "1MsEbXvTs8mHy5vS9hgyMPq5Xx4umiuYrX", "n": 0, "script": "76a914e4e2a9a247f46c81fa2cc33523ccfac977a370c588ac", "spent": false, "tx_index": 355525333, "type": 0, "value": 1430000492 }, { "n": 1, "script": "6a24aa21a9edb744306372d97b47e5f81708eb8a2e3ef1790c0a128345008e2eb299400e68b1", "spent": false, "tx_index": 355525333, "type": 0, "value": 0 } ], "relayed_by": "0.0.0.0", "size": 241, "time": 1529486188, "tx_index": 355525333, "ver": 1, "vin_sz": 1, "vout_sz": 2, "weight": 856 } |
Видно, что некто перечислил 14.3 BTC кому-то. Именно так: кошельки отправителя и получателя представлены в виде хэшей, и кто это такие — мы не знаем. Собственно это и есть краеугольный камень БитКойна.
Блокчейн хранит абсолютно все транзакции, которые были в системе. По этой причине совершенно четко видно, как появляются монеты и к кому они переходят, и какое общее количество их находится в системе.
На этом завершим наш небольшой анализ, ведь главное мы уже сделали: показали как вагончики сцепляются друг с другом и уникальность этой сцепки.
Когда в адресной книге Google набирается несколько тысяч клиентов, становится тяжеловато ворочать этим объемным списком. Импорт/экспорт в странички Excel становится неудобным; кроме того появляются CRM-подобные приложения, в которых хотелось бы интегрировать самые разные базы данных, в том числе и контакты Google. Значит, пришло время доступиться к нашим контактам через консольные приложения, используя Google Contacts API.
Получение списка контактов
Используя API, мы можем не только получить список контактов, но также и видоизменять и дополнять его. В простейшем случае, первые 150 записей из адресной книги можно вытащить так, вбив это в адресную строку браузера:
|
|
https://www.google.com/m8/feeds/contacts/default/full?access_token=ACCESS_TOKEN &alt=json&max-results=150&start-index=1 |
Можно догадаться, что данные мы получим в формате json, что понятно, поскольку каждой записи в адресной книге соответствует куча полей, также понятно сколько записей будет выведено. И поскольку здесь нет ни нашего логина, ни пароля, можно предположить, что ACCESS_TOKEN — это та самая строка, которая обеспечивает авторизацию. Чтобы понять, как эта авторизация работает, мне в свое время пришлось выполнить несколько танцев с бубном. В этой статье делюсь результатами своих изысканий.
Регистрируемся в Google
Предполагаю, что у вас уже есть Google-аккаунт, или электронная почта. Логинимся на страничке Гугла и идем по адресу https://console.developers.google.com/cloud-resource-manager , где создаем новый проект. Даем ему произвольное название, например Beerware. Дальше переходим в другое место https://console.developers.google.com/apis/credentials. Жмем кнопочку «Создать учетные данные» и выбираем «Идентификатор клиента OAuth», и дальше отмечаем «Другие типы». Дадим название идентификатору — скажем Beerware Script.
Не спрашивайте меня, что означает разнообразие в выборе различных опций. Погружаться в это можно долго, важно лишь что наш вариант — рабочий.
Это все, что нужно было сделать в девелоперских панелях Гугла. Если вы нажмете на редактирование идентификатора, то увидите ID клиента и секрет клиента. Запомним эти названия, они понадобятся нам дальше. Чтобы не путаться с обозначениями при подстановке в другие строки, обозначим их CLIENT_ID и CLIENT_SECRET.
Authorization Flow: как проходит авторизация OAuth2
Конечной целью авторизации является получение ACCESS_TOKEN, который необходимо использовать каждый раз когда мы делаем запрос к адресной книге. Теперь нам нужно внимательно пройтись по всем этапам. Самая главная вещь, которая толком не описана в документации Google — какие этапы выполняются только один раз, а какие нужно выполнять периодически. Я буду это подчеркивать.
Каждый этап — это обращение к серверу Google по HTTPS и получение ответа. Детали запроса я распишу позже, сейчас главное — уяснить общую схему.
Получение кода авторизации
Код авторизации сразу ставит в тупик. Зачем он нужен, если уже есть CLIENT_SECRET? Разница в том, что код авторизации используется только один раз — для получения токенов. Замечу сразу, что если вы попытаетесь получить по одному и тому же коду авторизации токены еще раз, то получите ошибку. Таким образом, код авторизации действителен пока мы еще не получили токены. После их получения он сразу «протухает». Но об этом — дальше.
CLIENT_SECRET, как и CLIENT_ID — постоянные строки, скрытые в нашем приложении вдали от посторонних глаз.
Итак, посылаем на сервер CLIENT_ID, CLIENT_SECRET и получаем код авторизации. Назовем его AUTH_CODE.
Получение токенов
И снова заголовок наводит на размышления. Почему токены во множественном числе, когда вначале говорилось только об ACCESS_TOKEN? На самом деле, помимо этого токена, который используется при работе с адресной книгой, нам дают еще REFRESH_TOKEN. Его роль будет ясна ниже.
Посылаем на сервер CLIENT_ID, CLIENT_SECRET, AUTH_CODE и получаем парочку ACCESS_TOKEN, REFRESH_TOKEN.
Казалось бы, тут можно забыть о REFRESH_TOKEN, поскольку ACCESS_TOKEN у нас в руках, и дальше еще забыть и про авторизацию и спокойно пользоваться ACCESS_TOKEN во всех запросах. Я так поначалу и делал, только обнаружил что в один прекрасный момент сервер перекрыл мне доступ. В чем дело? А причина была в том, что по задумке Google время жизни ACCESS_TOKEN — всего лишь час, после чего он протухает и работать с ним не получится.
Что теперь, снова получать код авторизации и токены? Нет. Про эти два этапа «получение кода авторизации» и «получение токенов» можно полностью забыть и уже никогда к ним не возвращаться. Самое главное, что у нас есть — это REFRESH_TOKEN. Сохраните его в надежном месте, поскольку теперь кроме него нам ничего не нужно.
Замечу, что эти пройденные этапы мы выполняем лично. Наше приложение Beerware Script о них ничего не знает: ему нужны только токены.
Получение ACCESS_TOKEN по REFRESH_TOKEN
Дальше все становится просто. Когда ACCESS_TOKEN протухает, то есть через час становится не действительным, или просто не дожидаясь этого момента, мы посылаем на сервер CLIENT_ID, CLIENT_SECRET, REFRESH_TOKEN и получаем обновленное значение ACCESS_TOKEN, которое используем для запросов к серверу. Важно знать, что при этом REFRESH_TOKEN не меняется. Поэтому для приложения критично запомнить его, например в файле, при получении в самый первый раз.
Все этапы авторизации из командной строки
Для различных языков есть соответствующие библиотеки OAuth2. Мы же, для ясности изложения, все будем делать ручками из командной строки, формируя запросы с помощью утилиты curl. В конце концов, все эти библиотеки делают тоже самое — формируют url запросы к серверу Google.
Начнем с получения кода авторизации. Поскольку эта процедура выполняется только раз, не грех поработать вместо нашего приложения. Вбиваем в адресную строку броузера и наблюдаем:
|
|
https://accounts.google.com/o/oauth2/auth?сlient_id=CLIENT_ID &redirect_uri=http://localhost:8080 &scope=https://www.google.com/m8/feeds/&response_type=code |
Запросом response_type=code мы хотим увидеть код авторизации. Он будет переслан по адресу redirect_uri, а поскольку на URI=http://localhost:8080 ни у меня, ни думаю у вас — ничего нет, то естественно браузер даст ошибку. Но это неважно, поскольку искомый код появится в адресной строке браузера и мы возьмем его оттуда, копируя начиная с code= и продолжая до символа #, который присутствует в конце url. Так мы получаем AUTH_CODE.
В середине процедуры вас может пробросить на страницу авторизации, где вы должны подтвердить доступ к адресной книге со стороны проекта Beerware.
Теперь получаем токены. На запрос
|
|
curl -X POST -d "code=AUTH_CODE&client_id=CLIENT_ID &client_secret=CLIENT_SECRET&redirect_uri=URI &grant_type=authorization_code" https://accounts.google.com/o/oauth2/token |
сервер выдаст нам долгожданную парочку токенов:
|
|
{ "access_token" : "XXXXXXXXXXXXXXXX", "expires_in" : 3600, "refresh_token" : "XXXXXXXXXXXXXXXX", "token_type" : "Bearer" } |
Если мы попробуем получить токены еще раз, с использованным кодом авторизации, нас ожидает ошибка:
|
|
Authorization code redeemed |
Все, код авторизации протух и с ним уже сделать ничего нельзя!
На этом ручная работа закончилась и скрипт Beerware Script может начинать работу. Отдаем ему ACCESS_TOKEN и REFRESH_TOKEN и забываем про авторизацию. Все, что нужно делать скрипту когда ACCESS_TOKEN становится недействительным — это получить его новое значение запросом
|
|
curl -X POST -d "client_id=CLIENT_ID &client_secret=CLIENT_SECRET &refresh_token=REFRESH_TOKEN &grant_type=refresh_token" https://accounts.google.com/o/oauth2/token |
Само собой, это будет уже не утилита curl, а https запрос с соответствующей библиотеки нашего приложения Beerware Script.
После запроса мы получим новый ACCESS_TOKEN:
|
|
{ "access_token" : "XXXXXXXXXXXXXXXX", "expires_in" : 3600, "token_type" : "Bearer" } |
Поработаем с адресной книгой
Теперь самое время посмотреть, как будет выглядеть работа со списком адресов. Как обычно, на этом этапе нам ассистирует Python. Ниже — фрагменты скрипта Beerware Script, которые дают представление об общей идее работы с полученным списком.
Вначале затребуем список:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#!/usr/bin/python import json import requests access_token = 'XXXXXXXXXXXXXXXX' # область работы scope - с Google Contacts scope = 'https://www.google.com/m8/feeds' server = "https://www.google.com/m8/feeds/contacts/default/full?access_token=%s&scope=%s&alt=json" # получаем кусок адресной книги используя access_token r = requests.get(server % (access_token,scope)) # это может пригодиться для отладки, если мы захотим увидеть ответ сервера при ошибке # print(r.content) # обычный результат запроса # 200 = Ok # 403 = ошибка авторизации, самое время обновить access_token! # но этот код вы напишете сами print(r.status_code) # получили адресную книгу в виде структуры dict data = json.loads(r.text) |
В комментах видно, в каком месте нужно ловить ошибку авторизации, когда ACCESS_TOKEN устареет. Дальше нужно что-то делать с полученным списком адресов, наверное самое очевидное — это получить номера телефонов.
Делается это в цикле по всей структуре data:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# все искомое расположено ниже уровней feed, entry # цикл по контактам for r in data['feed']['entry']: # распечатаем весь контакт: просто для наглядности и отладки print(json.dumps(r, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ': '))) # вытаскиваем имя контакта name = r['title']['$t'].encode('utf-8') # если контакт пустой, все пропускаем if name == '': continue print(name) # страхуемся: а вдруг у контакта нет телефона? тогда вылетим из скрипта с ошибкой if 'gd$phoneNumber' in r: # зачем цикл? а потому что телефонных номеров может быть больше одного for t in r['gd$phoneNumber']: phone = t['$t'].encode('utf-8') print("\t%s" % phone) |
В результате после работы скрипта получим список контактов, где под каждой фамилией будет список телефонов. Тема отдельного рассмотрения — как изменять существующие контакты и заводить новые. Это решается засылкой на сервер соответствующей xml записи. Подробно процедура описана здесь. Думаю, вы и сами отлично справитесь с этой задачей )
Согласованную фильтрацию можно рассматривать как во временной, так и в частотной области.
Чтобы фильтр был согласованным по отношению к сигналу, его импульсная характеристика должна быть зеркальным отражением сигнала по оси времени. Этот принцип несет определенный физический смысл: чтобы свертка сигнала и импульсной характеристики фильтра была максимальной, импульсная характеристика должна быть расположена именно таким образом.
Еще нагляднее физический смысл проявляет себя в частотной области: согласованный фильтр «доворачивает» спектральные составляющие сигнала ровно настолько, чтобы они складывались синфазным образом, достигая максимального выходного эффекта. Чтобы доворот происходил в направлении компенсации, используется комплексно-сопряженное значение передаточной функции фильтра.
Часто реализацию согласованного фильтра выполняют в частотной области, используя наработанные библиотеки быстрого преобразования Фурье (БПФ).
Вот пожалуй и все, что хотелось бы сказать про согласованный фильтр (СФ). Поехали дальше.
От времени к пространству
Что скажете, если мы займемся фильтрацией пространственных данных? Это немного непривычно, поскольку мы обычно связываем сигнал с изменениями во времени. С другой стороны, когда смотрим на график этого сигнала то видим только рисунок, и ничего более. И фактически работаем с этим рисунком. Только это будет одномерная обработка, где ось времени будет просто абстрактной осью x.
С двумерными изображениями физический смысл ускользает. Как представить этот сигнал изменяющимся во времени, когда он содержит уже две «псевдовременные» оси? Поэтому нам лучше оторваться от привязки ко времени и воспринимать сигнал тем, чем он является — 2D изображением. Что интересно, для многомерных сигналов также существует понятие пространственных частот, и это активно используется при изучении работы объемных антенных решеток.
Маджонг: найти кубик
Чтобы наше повествование не выглядело слишком солидным и серьезным, выберем в качестве входного сигнала изображение россыпи кубиков Маджонг:
 Исходная сцена для поиска кубика, соответствующего шаблону Поставим себе задачу: найти в этой россыпи определенный кубик, например такой:
 Шаблон для поиска Как вы догадались, этот кубик, который я буду использовать в качестве шаблона, просто скопирован из исходной сцены — россыпи. Вот кстати, можно сразу немного поиграть в Маджонг: найдите этот шаблон на сцене!
При этом будем считать, что окружающие кубик куски — это тоже часть шаблона. Не будем обрезать его до идеального, ведь лучшее — враг хорошего )
Замечу лишь, что лишние кусочки точно также содержатся во входной сцене, поэтому алгоритму все равно: это мы видим кубик с лишними кусками, а программа — просто прямоугольник с неким изображением.
Теперь пришло время дать правильные названия всем действующим лицам и участникам.
Кто есть кто
Итак, наша сцена — это смесь сигнала и помехи. Сигнал — кубик, который мы заприметили (надеюсь что вы уже увидели его на сцене), все остальное — это помеховый фон.
Наша задача: найти этот кубик на сцене с помощью 2D согласованного фильтра, и не только найти, но и сразу определить его местоположение. Структура СФ будет определяться шаблоном для поиска — этим же кубиком, который на этот раз сам по себе.
Поскольку в этой задаче нет никакого времени, попробуем обозначить шаги ее решения в частотной области. СФ работает следующим образом:
|
|
# SCENE: спектр исходной сцены (сигнала+помеха) # REF: спектр шаблона, или сигнала для которого ищется соответствие # OUT: спектр выходного сигнала OUT = SCENE*np.conj(REF) # выходной сигнал согласованного фильтра как обратное преобразование Фурье out = np.abs(np.fft.ifft2(OUT)) |
В результате, компоненты сцены соответствующие шаблону попадут на выход фильтра, а те компоненты которым нет соответствия будут подавлены. Все достаточно просто.
Перед фильтрацией необходимо найти пространственные спектры сцены и нашего опорного кубика:
|
|
# scene: 2D массив, изображение сцены # ref: 2D массив, изображение кубика SCENE = np.fft.fft2(scene) REF = np.fft.fft2(ref) |
Запускаем интерпретатор Питона (да, это был именно он) и смотрим на результаты.
Результат работы согласованного фильтра 2D
Я добавил в программу небольшой вспомогательный код, чтобы отмечать зеленой рамкой на сцене месторасположение максимального отклика на выходе СФ. На рисунке сцена (сигнал+шум) расположена слева, отклик согласованного фильтра — справа. Белый цвет соответствует максимальному отклику.
 Результат работы согласованного фильтра 2D для поиска шаблона На картинке отклика СФ хорошо видна яркая точка, соответствующая пику выходного сигнала. Ее расположение в точности соответствует положению верхнего левого угла шаблона. Поэтому можно сказать, что с задачей мы справились: нашли совпадающий кубик по шаблону, или отфильтровали помеху от сигнала, используя опорный сигнал.
Я также провел второй эксперимент, в котором поставил на сцену шаблон еще раз, в другом месте. По идее, СФ должен показать наличие двух согласованных с опорным сигналов. Так оно и есть: на картинке отклика СФ наблюдаем две яркие точки, соответствующие положению двух шаблонов на сцене.
 Результат работы согласованного фильтра 2D со сценой, содержащей два шаблона Интересное наблюдение: на картинке отклика СФ наблюдается небольшое светлое пятно, соответствующее определенному совпадению с сигналом шаблона. Я долго не мог понять, что он там нашел, а потом догадался: ведь искомый кубик имеет повторяющуюся структуру, и этой области немного не хватило рисунка, чтобы продолжить следующие шесть точек на юго-восток. Совпадение получилось только наполовину, что дало всплеск на выходе СФ.
Может возникнуть такой вопрос: если помеха отфильтрована, почему на выходе СФ мы не наблюдаем чистый сигнал? Вот такой он, согласованный фильтр: использует всю информацию о сигнале, и на выходе ее уже не остается. Только уровни, которые только и остается что сравнивать. Если бы на выходе мы наблюдали признаки формы сигнала, это означало бы, что СФ не использовал эту информацию в обработке.
Также открою маленький секрет: выход СФ есть не что иное, как двумерная корреляционная функция сцены и шаблона.
Эта статья — аэродром подскока, который мы используем позже, когда начнем распознавать маркеры системы автоматической визуальной посадки беспилотников. Эта игрушка будет посильней Маджонга!
Вот мы наконец и добрались до этого метода. Литературы по этой технике — целая куча, но как обычно смысл ускользает. Само описание MUSIC достаточно простое: это поиск экстремума произведения двух матриц. Однако что происходит внутри этих матриц — с этим нам предстоит разобраться.
Эту тему довольно сложно понять с нуля, не имея относительно прочной опоры в линейной алгебре. Поэтому нам понадобится аэродром подскока — пара статей, которые я написал ранее: собственные числа и векторы в поиске закономерностей. Метод главных компонент и ковариационная матрица и линейная трансформация. Прочитайте их еще раз, и мы детально, шаг за шагом совершим увлекательное путешествие по пространствам (в буквальном, математическом смысле), а путеводителем для нас будут собственные числа и векторы матриц, которые описывают преобразования этих пространств. Как обычно, ассистировать нам будет Python: строгая нотация языка программирования не допустит никакой двусмысленности, особенно в описании структуры и размерности матриц, чем частенько грешат различные статьи.
Будем рассматривать один частный случай — пример входного сигнала для алгоритма, и на основе этого случая будем делать обобщения на все возможные случаи. За доказательством справедливости этих обобщений отсылаем дотошных читателей к многочисленной литературе; здесь во главу угла поставлена простота и доходчивость изложения.
Компактный симпатичный спектр из двух частот
Зададим исходные данные. Будем иметь дело с сигналом, состоящим из двух частот; также подмешаем немного шума, для реальности происходящего:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# импортируем то что необходимо import numpy as np import scipy.linalg as LA # количество выборок сигнала N = 8 m = np.arange(N) # количество полезных сигналов P = 2 # матрица сигналов x = np.zeros((N, P+1), dtype='complex') # первый сигнал: частота f=3 x[:,0] = 1.0*np.exp(1j*3.0*2.0*np.pi*m/N) # второй сигнал: частота f=5 x[:,1] = 0.8*np.exp(1j*5.0*2.0*np.pi*m/N) # помеха: белый шум x[:,2] = 0.5*np.random.randn(N) |
На самом деле, мы будем наблюдать смесь этих сигналов, и наша задача — определить какие частоты присутствуют в его спектре. Поэтому наблюдаемый сигнал X будет суммой этих массивов:
Суммирование идет по выборкам, о чем говорит выбор оси axis=1. Поэтому размерность полученной матрицы будет N x 1.
Как и во многих алгоритмах линейного предсказания, в том числе и в MUSIC, конкретная реализация сигнала не представляет большого интереса. Гораздо более важной и обобщенной характеристикой является корреляционная, а точнее автокорреляционная матрица Rxx, выявляющая внутренние связи во входных данных X:
|
|
XT = np.mat(LA.toeplitz(X)) Rxx = XT*XT.H |
Update:
Матрица Теплица использована для удобства расчета автокорреляционной матрицы, каждый элемент которой представляет собой dot-продукт сигнала sig и его смещенной копии. Чтобы не делать смещение в цикле, с помощью матрицы Теплица входной сигнал (вектор Nx1) превращается в заготовку — матрицу XT размером NxN, которая уже содержит все допустимые сдвиги сигнала sig от 0 до N-1.
Остается только получить dot продукт этой заготовки обычным выражением dot=XT*XT.H
А теперь — прощай, сигнал X! В нашем алгоритме ты нам больше не понадобишься. Вместо тебя будет работать твоя корреляционная матрица Rxx. Сразу скажу, что быть на сцене ей тоже осталось недолго: после того как мы находим собственные числа en и векторы ev корреляционной матрицы Rxx, она тоже перестает быть нужной:
Гарантирую, что с этого момента вы потеряли нить и вам расхотелось читать дальше ) Поэтому самое время остановиться и понять смысл того, что мы делаем. Тем более что большую часть алгоритма мы уже прошли: осталось фактически только одно последнее действие ) Вот она, обманчивая простота матриц!
Итак, наступил обещанный момент погружения в матричные пространства.
Зачем нужны собственные числа и векторы
Идея метода MUSIC состоит в разделении пространства входных сигналов на сигнальную часть и помеховую. Для пространства сигналов существует свой базис, в котором может быть разложена корреляционная матрица Rxx. Поскольку Rxx является самосопряженной (сравниваем Rxx и Rxx.H в Питоне — это одно и то же), то базис разложения будет ортогональным и будет представлять из себя не что иное, как собственные векторы матрицы, масштабированные собственными числами. Что такое ортогональное разложение вы конечно же помните из школьной геометрии, когда рисовали проекции вектора на ортогональные оси x и y. Только это было двумерное пространство, которое легко представить геометрически, а в нашем случае размерности пространства N только и остается, что положиться на формулы.
Проверим, соответствует ли Rxx разложение по ортогональному базису:
|
|
EV = np.mat(ev) EN = np.mat(np.diag(en)).T print(EV*EN.H*EV.H) |
результат будет соответствовать Rxx.
Теперь мы можем предположить, что одна часть собственных векторов, участвующих в разложении Rxx, соответствует сигналу, а другая часть — помехе. Будем также держаться предположения, что полезных сигналов — P, а все остальное в количестве N-P это помехи или шум. Наше предположение некоторым образом подтвердят собственные числа, если мы расставим их в порядке убывания:
|
|
idx = en.argsort()[::-1] en = en[idx] # поскольку мнимая часть исчезающе мала, выводим только действительную print(en.real) [ 75.69 50.4 10.39 2.6 1.73 1.69 1.58 0.34] |
По собственным числам можно судить об уровне входных сигналов: как и ожидалось, первые P=2 это полезный гармонический сигнал, остальное — это помеха. Не откладывая на потом, сразу упорядочим и собственные векторы, чтобы они соответствовали собственным числам, расположенным по убыванию:
Теперь выстраиваем следующую логическую цепочку. Начало ей положит тот факт, что собственные векторы сигнала и помехи — взаимно ортогональны:
|
|
# пространство помехи: собственные векторы от P и выше EV = np.mat(ev[:,P:]).T # пространство сигнала: собственные векторы до P EVSignal = np.mat(ev[:,:P]) # проверка ортогональности print(EV*EVSignal) |
результат — вектор практически близкий к нулю, что и означает ортогональность.
Как следствие, пространства сигнала и помехи тогда тоже будут ортогональными и как результат полезный сигнал будет ортогонален пространству помехи. Или другими словами, проверка разложения сигнала на базис помехи, образованный ее собственными векторами, покажет ноль. В этом и есть суть метода, при этом естественно не зная составляющего сигнала, в методе он подменяется комплексным опорным экспоненциальным вектором, который является функцией частоты. Путем сканирования частоты подбирается такое значение этого вектора, при котором его разложение на базис помехи будет близок к нулю. При этом зафиксированное значение частоты будет соответствовать факту ее присутствия во входном сигнале.
Разложение экспоненциального вектора на базис помехи
Теперь все дело за тем, как правильно записать нотацию искомого разложения. Собственные векторы помехи мы уже выделили раньше: это вектор EV. Вектор комплексных опорных сигналов будет иметь размерность N:
|
|
ref = np.zeros(N, dtype=complex) |
Значения частот будем перебирать из диапазона:
|
|
f = np.arange(0,10,0.001) |
Абсолютное значение спектра будем находить как модуль разложения REF*EV.H*EV*REF.H.
Тогда полный цикл перебора опорного вектора будет выглядеть так:
|
|
for i in range(f.size): ref = np.exp(1j*2.0*np.pi*m*f[i]/N) REF = np.mat(ref) Mult=REF*EV.H*EV*REF.H Mmusic[i]=np.absolute(1/Mult) Mmusic = 10*np.log10(Mmusic/np.max(Mmusic)) |
Для удобства отображения графика, полученные значения масштабируются в логарифмическом масштабе.
Заметим еще раз: в цикле подбирается такое значение частоты, чтобы разложение опорного вектора в базисе помехи было максимально близко нулю. Это будет означать ортогональность по отношению к пространству помехи и как следствие — соответствие текущего опорного вектора одному из сигналов.
P показан на рисунке.
Начнем с P=2:
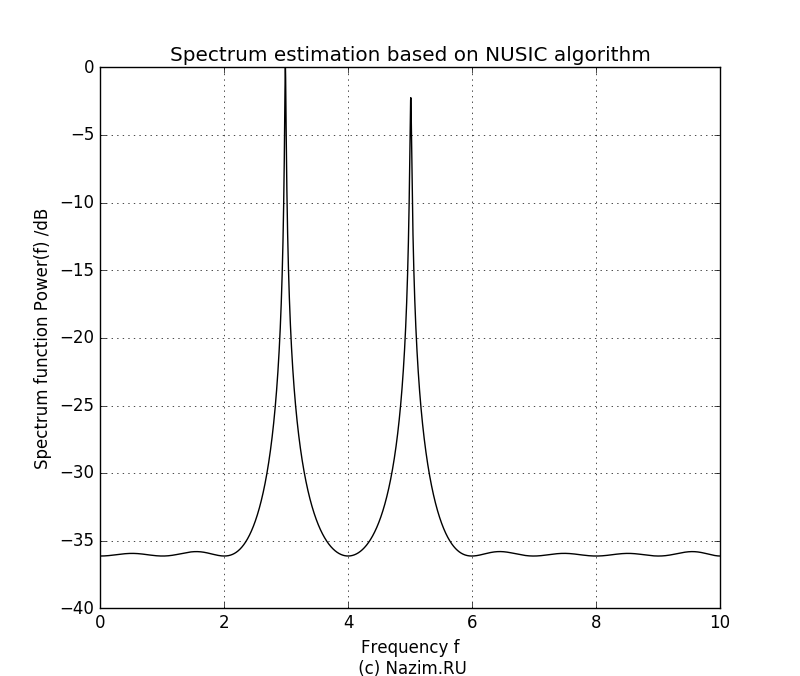 Оценка спектра MUSIC для P=2 Здесь неожиданностей нет. На рисунке четко видно два пика относительной частоты 3.0 и 5.0, причем уровень второго сигнала ниже. Мы четко определили наличие двух синусоид в комплексном сигнале в присутствии шума, причем получили значение частот этих сигналов и относительные амплитуды. Теперь возникает интересный вопрос: что произойдет если мы зададим P=1? По идее алгоритм должен посчитать за полезный только один сигнал, а вторую синусоиду вместе с шумом отнести к помехе. Так оно и есть:
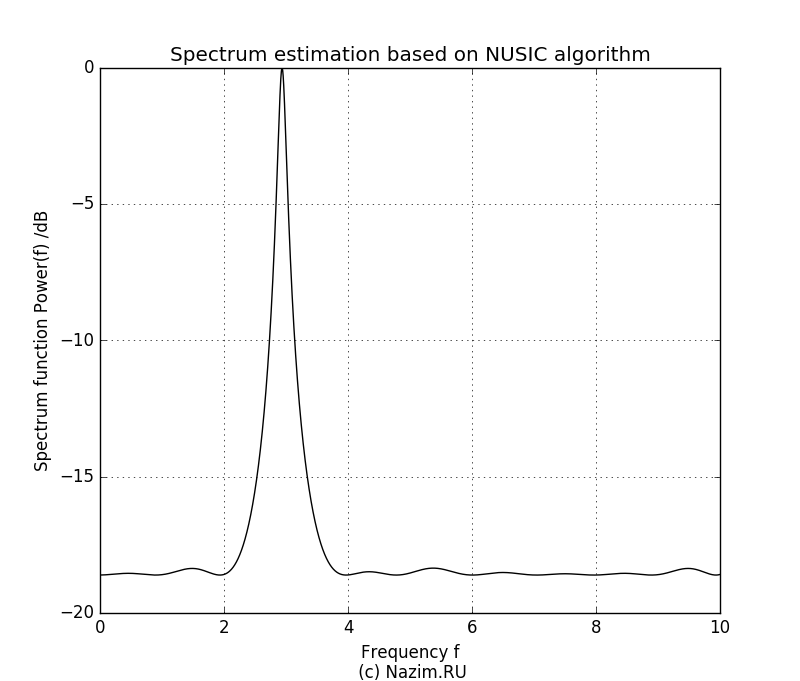 Оценка спектра MUSIC для P=1 Поскольку амплитуда второго сигнала была ниже, в пищевой цепочке собственных значений он оказался крайним и был подавлен. Остался только сигнал большей амплитуды с частотой 3.0.
Продолжаем эксперимент. Теперь предположим, что на входе три полезных сигнала, то есть P=3. Что произойдет если белый шум также будет засчитан на равных как нечто полезное?
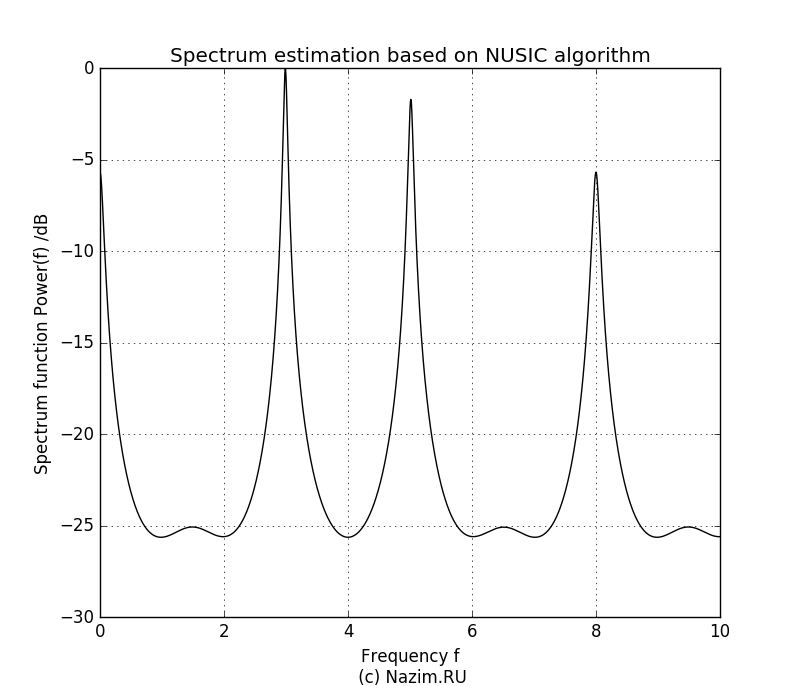 Оценка спектра MUSIC для P=3 Получилось довольно неприятно, но не смертельно. Третий всплеск конечно достаточно большой по амплитуде, и такой же всплеск наблюдаем на нулевой частоте. Но мы сами задали шуму приличный уровень — 0.5, так что метод MUSIC довольно лояльно относится к тому, что мы неточно определили количество полезных сигналов.
Продолжим расширять наше представление о количестве полезных компонент и зададим P=4:
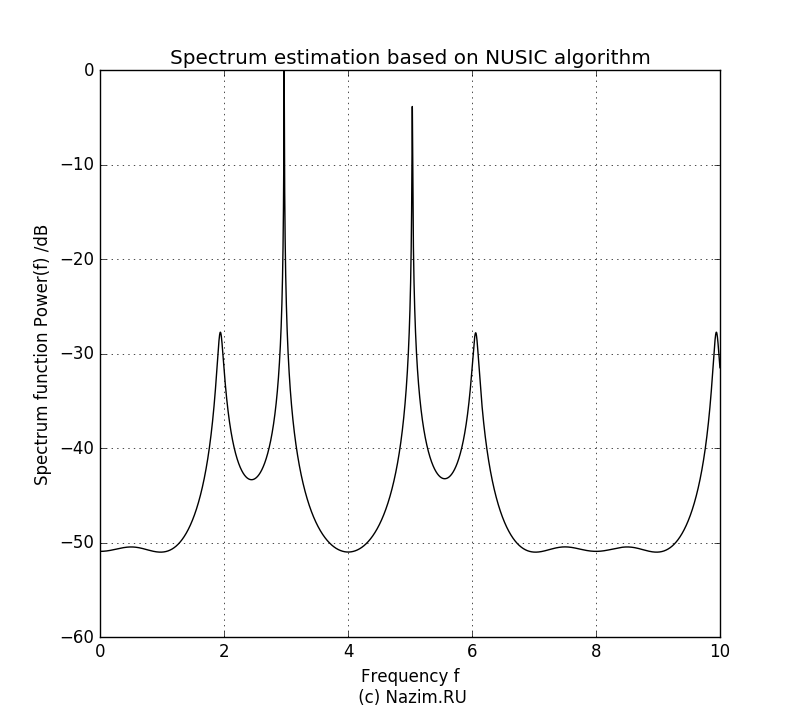 Оценка спектра MUSIC для P=4 Как ни странно, картинка стала даже еще лучше. Как и в предыдущих случаях, два полезных сигнала занимают максимум лепестков диаграммы, и хорошо заметно что ошибка в предсказании P дает ее заметное искажение.
Теперь, после того как мы использовали MUSIC для оценки частотного спектра, можно переходить к пространственным частотам — определению направления прихода сигнала, чем мы так любим заниматься в радиопеленгации. Об этом поговорим в следующей статье. И не забывайте что эта тоже была аэродромом подскока!
Историю современных радиопеленгаторов для аэропортов гражданской авиации можно отсчитывать от момента появления новой версии АРП «Платан» с процессорной обработкой и операционной системой. В то время было принято, что радиоприемные устройства (РПУ) — покупные «Юрки» будут компромиссным решением (за неимением радиоприемника своей разработки). Вначале разрабатываемое цифровое РПУ было частью пеленгационного проекта, но со временем руководство конторы решило выделить его в отдельное направление. Возможно, повлияло желание сделать унифицированный со связным приемник, хотя у каждой унификации есть своя цена. Но не будем забегать вперед )
По завершении разработки нового АРП «Платан» я переключился на собственные проекты, но продолжал интересоваться ходом модернизации пеленгатора, который должен был обзавестись своим радиоприемным трактом. И он появился: РПУ, более известное под названием ФИС, было выполнено на профессиональном уровне инженерами которые тогда еще работали в конторе (ну вот, снова вперед забежал). Классическая супергетеродинная схема с перестраиваемым преселектором обеспечивала отличные характеристики электромагнитной совместимости (ЭМС), такие как избирательность по соседнему каналу, подавление интермодуляционных продуктов. Ведь не секрет что эфир со временем не становится чище, и разнообразных помех, таких как профессиональные и любительские радиостанции, станций GSM, Wi-Fi и других становится все больше и больше. Поэтому обеспечение ЭМС выходит на первый план, тем более что современные радиокомпоненты позволили практически закрыть вопросы чувствительности АРП и улучшения отношения сигнал/шум.
Как и в АРП «Платан» с Юрками, так и с ФИСами у эксплуатации не было никаких нареканий. Но начиная с определенного времени, замечания посыпались. Вплоть до таких, как:
«у радиопеленгатора DF-2000 во время грозы, ложные пеленги на всех частотах. Думаем, что надо чувствительность прм. уменьшать,пока ждем ответа заводчиков» (с форума инженеров ЭРТОС).
На АРП с ФИС нареканий нет:
«У нас один из первых DF-2000 с ФИС ами. Ложных пеленгов на метеоявления, в отличии от АРП-75, не наблюдалось ни разу с 2008 года»
Это удивительно, потому что в радиопеленгаторе «Платан» была эффективная схема фазового обнаружения сигнала, которая давала очень низкие уровни вероятности ложной тревоги. И «пробить» ее на ложный пеленг, тем более при грозовых электромагнитных возмущениях, было нереально. Было очевидно, что что-то пошло не так. В конечном счете, причина была найдена: сбои в работе АРП DF-2000 были связаны с очередной модернизацией, а именно с заменой ФИС на цифровой приемник. Само собой, эта эволюция проходила уже без моего участия.
С этого места начинаем смотреть подробнее — как выполнен цифровой приемник, какая у него структура и где источник проблемы.
Цифровой радиоприемник в АРП DF-2000: тотальная «оптимизация»
Структурная схема пеленгационного приемника приведена на рисунке. Собственно говоря, это тот же самый приемник RS-2000, который используется в приемных центрах TRS-2000 производимых и поставляемых АО «Азимут». Разница лишь в фрагменте по правую сторону от АЦП — в программном обеспечении. И в том, что этот аппаратно одночастотный приемник превратился в РПУ, работающий на 4-х частотных каналах одновременно.
Ключевой аспект в этой истории — как раз слово «одновременно».
Конечно, сократить вчетверо объем радиоприемного оборудования — это хороший выигрыш по затратам. Рост стоимости радиопеленгатора идет за счет увеличения количества каналов, или РПУ. Вопрос лишь в цене: какими техническими характеристиками за это заплачено?
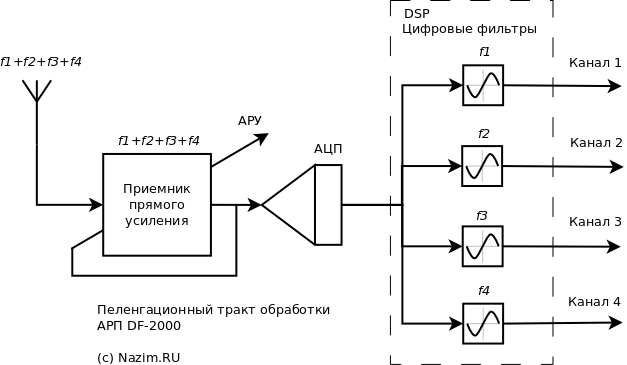 Аналоговая часть РПУ радиопеленгатора DF-2000 представляет приемник прямого усиления. Разделение частотных каналов происходит после оцифровки АЦП. Преселектор отсутствует, поэтому весь эфир из диапазона 118 -136 МГц поступает на вход АЦП.Внимание: такая схема построения подвержена блокированию и имеет плохие характеристики ЭМС! Смотрим тракт начиная с антенной системы. Принимаемый сигнал усиливается в приемнике прямого усиления, с помощью АРУ загоняется в диапазон входных сигналов АЦП, и далее цифровая обработка сигналов выделяет свой частотный канал, подавляя сигналы других радиостанций. Поскольку в отличие от классической супергетеродинной схемы здесь нет преселектора, подобная структура имеет все недостатки приемников SDR. В одной статье я уже ссылался на подробное описание этих недостатков, сделаю это еще раз:
«Основным недостатком, ограничивающим широкое применение подобного типа РПУ (с прямой оцифровкой сигнала с антенны — мое примечание), является невозможность обеспечения высоких уровней динамического диапазона по блокированию. Поскольку на входе АЦП отсутствует фильтрация, то АЦП соответственно не может выполнять оцифровку одновременно сигналов большого и малого уровня. В соответствие нормам ГОСТ радиоприемник должен обеспечивать уровень восприимчивости по блокированию не менее 126 дБ/мкВ для РПУ второго класса и 130 дБ/мкВ для РПУ первого класса. Очевидно, что существующие типы АЦП 14-16 бит не в состоянии обеспечить выполнение этого параметра.
Кроме этого, РПУ данного типа недостаточно качественно осуществляют обработку сигналов малых уровней. При приеме сигналов уровней чувствительности, рост ошибок квантования, вызванный недостатком разрядности АЦП, вызывает невозможность качественного приема. Естественно, что эти ограничения разработчики пытаются снижать конструктивными и программными средствами, но до появления на рынке высокочастотных АЦП с разрядностью не менее 24 бит, приемники данного типа не смогут соответствовать современным нормам по электрическим параметрам и составить полноценную конкуренцию аналоговым РПУ».
Поскольку приемник прямого усиления никак не защищает вход АЦП от помех, то сигналы любого радиопередатчика из диапазона 118 — 138 МГц и не только — будут напрямую давить на вход АЦП и снижать его реальный динамический диапазон. Чужие радиостанции, VOR, DVOR, даже импульсные сигналы локаторов — будут способствовать блокированию АЦП, и дальнейшая цифровая фильтрация будет бессмысленной. Собственно, этот процесс и наблюдается в эксплуатации.
АРП DF-2000 блокирует сам себя: принципиальные ошибки построения тракта обработки
Вернемся к нашему рисунку. Проведем мысленный эксперимент: будем наблюдать одновременное прохождение пеленгуемых частот f1, f2, f3, f4 через приемный тракт. При этом создадим для АРП льготный режим: представим, что помех вообще никаких нет, то есть в районе аэродрома выключены все связные и радионавигационные устройства. И представим, что эти сигналы имеют одинаковый уровень: на связь одновременно вышли четыре борта с одинаковой мощностью радиостанции и на одинаковом расстоянии.
С антенны все четыре сигнала усиливаются в приемнике прямого усиления и подаются на вход АЦП. Автоматическая регулировка усиления (АРУ) наблюдает суммарный сигнал и не в состоянии различать сигналы по частотам, поэтому к 16-разрядной сетке АЦП будет приведена сумма сигналов f1, f2, f3, f4 и как результат каждый из них будет подавлен в 4 раза. Я хочу подчеркнуть еще раз: все, что находится в эфире в полосе 118 — 136 МГц — свои сигналы с борта и многочисленные источники излучения в этом диапазоне, будет усилено и поступит на вход АЦП, поскольку в АРП DF-2000 приемник не имеет преселектора, то есть 2 бита из 16 динамического диапазона АЦП мы уже потеряли. В цифровой части после АЦП помеховые сигналы отфильтровываются четырьмя фильтрами, каждый из которых настроен на частоту канала пеленгования, и извлекается пеленгационная информация. Пока все ОК.
Теперь изменим исходные условия и сделаем их приближенными к реальности. На высоте 10000м на дальности 350км летит борт, который выходит на связь. Такая дальность для АРП не диковинка: ее максимальное значение при такой высоте и мощности радиостанции 5Вт по ТТЗ составляет 360км. Поэтому радиопеленгатор должен отработать без проблем. Поскольку приемник прямого усиления DF-2000 усиливает все подряд в диапазоне 118 — 136МГц, на входе АЦП будет все, что работает в этой широкой полосе в районе аэропорта. Не будем считать мощные помехи от VOR, DVOR, а также гармоники мощных сигналов первичных и вторичных радиолокаторов. Ограничимся рассмотрением передатчиков местного приемо-передающего центра; предположим что в определенный момент на передачу выходят одновременно 8 радиостанций. Тогда на входе АЦП будет смесь слабого сигнала с борта и мощных радиостанций центра.
Вообще-то такие условия не вызывают затруднения для классического супергетеродинного РПУ или цифрового приемника с преселектором. В первом случае посторонние сигналы будут просто подавлены в тракте промежуточной частоты, во втором — ослаблены в преселекторе. Главное — чтобы сигналы не блокировали друг друга, тогда сохраняется возможность фильтрации.
В нашем случае главный подозреваемый на блокирование — АЦП. Если его небольшой динамический диапазон будет перегружен, то никаких нормальных сигналов на выходе мы не увидим.
Продолжаем наши опыты ) Для того, чтобы попасть в динамический диапазон, приемнику придется задействовать АРУ таким образом, чтобы сумма сигналов на входе АЦП не превысила максимального значения. При этом необходимо контролировать не суммарную мощность, а амплитуду. За счет биений суммарный сигнал максимальной амплитуды будет равен сумме амплитуд полезного сигнала и помехи.
Как и в предыдущем примере, АРУ откалибрует суммарный сигнал только по самому сильному составному — в нашем случае по помехам которые создает передающий центр. Усиление будет достаточным только для прохождения помех, а наш сигнал с борта потеряется на уровне младших битов АЦП.
Говоря другими словами, в четырехканальном тракте частота самого сильного сигнала блокирует сигналы более слабых передатчиков. То есть, в этом случае никакой «одновременной» работы четырех каналов радиопеленгатора не получается.
Это гипотеза, осталось подкрепить ее цифрами.
Считаем уровни
Найдем соотношение полезного сигнала и помех. В качестве помехи, как мы условились раньше, будем считать 8 передатчиков передающего центра, расположенные от АРП на расстоянии 500м. Для расчета будем пользоваться зависимостью потерь распространения в свободном пространстве FSPL (Free Space Path Loss, потери распространения в свободном пространстве):
^2")
Разница в дальностях до борта и передающего центра дает искомое соотношение; для R1=350км, R2=0.5км получаем:
^2=490000=56.9dB")
Теперь нужно учесть разницу между мощностями сигналов бортовой и наземных радиостанций, которая составит 100 Вт (земля)/5 Вт (борт) = 20 = 13dB, итого суммарно разница между сильным и слабым сигналом на входе АЦП составит 56.9+13=69.9dB.
По напряжению разница 69.9dB составит 3126 раз. Уточним еще раз: это разница между уровнем по амплитуде одной радиостанции передающего центра и радиостанции борта на входе АЦП. Теперь надо учесть, что радиостанций — восемь. При одновременной передаче максимальные амплитуды суммируются, поэтому разница в уровнях станет еще больше — 3126*8 = 25008. Что там с нашим динамическим диапазоном АЦП? Для 16 разрядов он равен 65536. После того как АРУ уместит суммарный пеленгуемый сигнал в разрядную сетку АЦП, для сигнала борта останется 65536 / 25008 = 2,62 уровня. Это практически 1 бит АЦП, который работает на уровне шума! Для сигнала работает только 1 бит АЦП: вот оно, блокирование.
Заметьте, что теперь нет смысла говорить про частотное разделение сигналов: сигнал с борта до фильтра просто не дойдет. Таким образом, в такой помеховой обстановке АРП DF-2000 борт просто не увидит. Что и наблюдается на практике.
Снова не могу удержаться, чтобы не заметить, что радиотехнику должны разрабатывать не программисты, а инженеры ) Концепция «все загоним в цифру а там уже разберемся» не работает. Как следствие — на выходе дешевое как в смысле стоимости, так и в смысле параметров изделие. Инженеры ушли, оптимизаторы остались.
А жаль, хороший пеленгатор был вначале.
 Антенная решетка локатора AN-APG-81 самолета F-35 Бортовые радиолокаторы военных самолетов, предназначеные для поиска и сопровождения целей проходят эволюцию от пассивных фазовых антенных решеток (ПФАР, или PESA — Passive Electronically Scanned Array) к активным фазовым антенным решеткам — АФАР, или AESA: Active Electronically Scanned Array). Базовым элементом и тех и других является приемо-передающий модуль — Transmit/Receive Module, TRM. И если в пассивной решетке он практически в единственном экземпляре, то в активной на каждый элемент приходится по одному TRM.
В локаторе AN/APG-81 истребителя-бомбардировщика F-35 дотошные юзеры насчитали 1676 элементов; можно представить какой объем оборудования займут TRM и какова будет стоимость. АФАР — удовольствие не из дешевых! Но и возможности по сравнению с ПФАР неизмеримо выше: одновременное сопровождение нескольких целей, сканирование произвольных областей пространства, произвольный выбор сигналов и многое другое. Но нас в данном случае интересует не количественное увеличение сложности АФАР, а принципиальные изменения в тракте обработки сигнала, которые за ним последовали.
 Transmit-Receive Module, T/R модуль На фото слева показан T/R модуль, возможно даже от F-35. Каждая сборка обслуживает несколько элементов антенной решетки и содержит малошумящие усилители LNA (цепь приема) и усилители мощности HPA (цепь передачи). Переключение на прием/передачу производится по внешним сигналам управления. Сигнал, принимаемый элементом антенной системы, усиливается LNA и подвергается аналого-цифровому преобразованию. Дальнейшая обработка идет в бортовом сигнальном процессоре.
АФАР/AESA и ПФАР/PESA: что за чем следует
Мы хотим выявить теоретические и практические отличия в образовании диаграммы направленности активной и пассивной антенных систем. В соответствии с принципом обратимости нет разницы, для какого режима — прием или передача проводить анализ, это во первых, и во вторых интересующий нас вопрос блокирования относится сугубо к приему АФАР. Поэтому рассмотрим, как работает диаграммообразующая система (ДОС) в обоих случаях — для AESA и PESA.
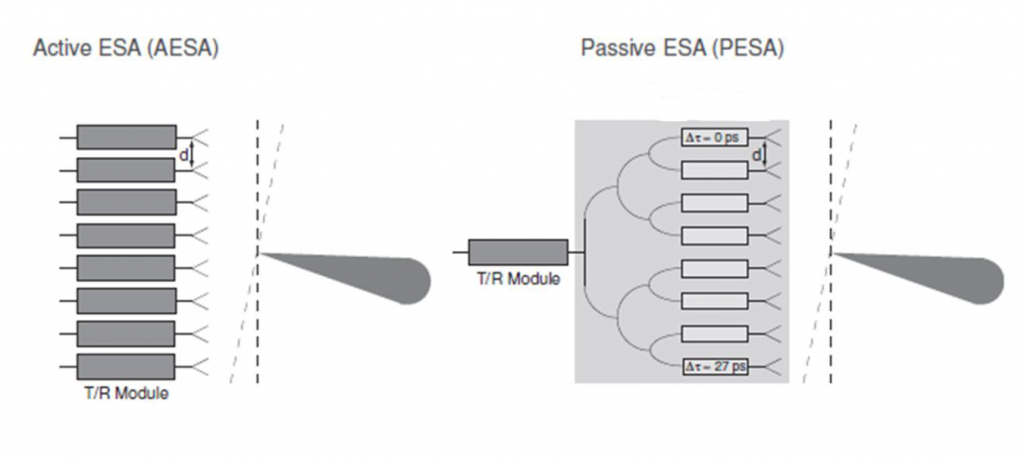 Расположение T/R модулей по одношению к диаграммообразующей системе. В АФАР/AESA (активная решетка) T/R модули располагаются до ДОС, в ПФАР/PESA (пассивная решетка) T/R модуль располагается после ДОС. В АФАР фазовый сдвиг вносится в компьютере, в ПФАР — с помощью управляемых фазовращателей В АФАР сигнал элементов антенны принимается T/R модулями и поступает в сигнальный процессор, который назначает каждому элементу АФАР весовой коэффициент и фазовый сдвиг, после чего после численной обработки все сигналы суммируются. Синфазное суммирование, дающее максимальный сигнал будет формировать основной лепесток диаграммы; сигналы с других направлений будут складываться неоптимальным образом, давая на выходе невысокие уровни, которые мы называем боковыми лепестками.
В ПФАР фазовый сдвиг вносится процессором физически, с помощью фазовращателя через который подключен элемент антенной системы. В этой же антенной системе сигналы суммируются до сигнального процессора, избавляя последний от необходимости производить расчет по каждому элементу ПФАР. В результате точно также формируются основные и побочные лепестки.
То обстоятельство, что АФАР за счет управления амплитудой сигнала антенного элемента может точнее и лучше формировать диаграму по сравнению с ПФАР, является несомненным преимуществом но не играет существенного значения с точки зрения целей нашего рассмотрения.
Итак, математическая процедура ДОС в случае активной и пассивной решетки совершенно идентична: разница лишь в том, что в локаторе с АФАР формирование диаграммы производится в вычислителе, а в локаторе с ПФАР — аппаратно в самой антенной системе. Таким образом, теоретических различий между этими способами реализации — никаких. С практической точки зрения, особых проблем тоже как-бы не видно. Но это только на первый взгляд.
Сейчас мы пришли к той точке, когда программисты, поставив этот знак равенства, успокаиваются и идут пить кофе, а инженеры начинают беспокойно ерзать на своих стульях. И это неспроста! Инженеры знают, что полная аналогия между программной и аппаратной обработкой оправдана только тогда, когда приемный тракт является линейным по отношению к входным сигналам. В реальных же условиях, тем более с учетом радиолокационного противодействия, это может быть совсем не так. И тут уже появляется принципиальная разница в поведении ДОС у активной и пассивной решетки, и эта разница совсем не в пользу АФАР. Приступаем к эксперименту.
Ставим помеху, или как jamming портит красивую картинку
Эксперимент будет проходить следующим образом. Устанавливаем источник помехи и будем наблюдать, какое воздействие это возымет на АФАР и ПФАР. Требования к помехе не сильно жесткие: достаточно, чтобы ее мощность создавала достаточный уровень в динамическом диапазоне T/R модулей; тип модуляции не принципиален, частота тоже: достаточно чтобы она была в достаточно широкой полосе пропускания антенных систем. Расположение источника помехи тоже некритично: достаточно лишь, чтобы он находился в диапазоне углового сканирования радиолокатора.
На этом этапе, вслед за программистами уходят пить кофе менеджеры и журналисты. Ведь они прекрасно знают, что для этого и формируется диаграмма направленности, чтобы подавлять подобные помехи. Более того, АФАР прекрасно может запеленговать источник и сформировать диаграмму таким образом, чтобы в направлении помежи был нулевой уровень диаграммы. Поэтому помеха будет подавлена провалом в сформированной диаграмме направленности. Тоже на первый взгляд.
Да, это действительно так, но… опять таки справедливо только тогда, когда тракт приема является линейным. Если помеха является блокирующей, то есть нарушающей линейность тракта, то благостная картинка просто перестает существовать. В ГОСТах, которые формируют требования к профессиональной радиоприемной технике, этот параметр так и называется — блокирование, который определяется как «изменение отклика на полезный радиосигнал при наличии на входе радиоприемного устройства хотя бы одной радиопомехи». Заметьте: в линейной системе сигнал и помеха суммируются независимо друг от друга, поэтому отклик на полезный сигнал не меняется в зависимости от помехи. Это может произойти только в том случае, если помеха нарушает линейность приемного тракта, в нашем случае — приемной цепи T/R модуля, состоящей из LNA и АЦП.
В ПФАР диаграммообразующая система (ДОС) находится до T/R модуля, поэтому последний защищен от блокирующей помехи диаграммой направленности. В идеальном варианте, как было подмечено выше, если источник помехи попадает в ноль диаграммы и на входе T/R модуля она будет равна нулю. Это принципиальный момент, на который я обращаю ваше внимание.
В АФАР ДОС находится после T/R модулей, вследствие чего они беззащитны перед сигналами на своих входах. Минимумы диаграммы подавляющие помехи будут вычисляться также после этих модулей, и поэтому если они будут блокированы, то полезный сигнал на выходе этих модулей просто не попадет — никакие фильтры не помогут.
Постойте, но ведь проблема известна давно. И если покопаться в старинных книжках, то можно найти решение. И действительно, в аналоговой технике радиоприема защитой от блокирования служит большой динамический диапазон, который позволяет проходить маленькому сигналу на фоне неизмеримо более мощной помехи без искажений, что дает возможность отфильтровать помеху в дальнейшем. Такого же подхода можно было ожидать и от приемника TRM — но наличие АЦП в тракте рушит все надежды, и сейчас скажу почему.
Часто можно привести цитату, в которой проблема сформулирована лучше, чем ее можешь сформулировать ты. Сейчас как раз такой случай, поэтому процитирую первоисточник. Он как раз указывает на проблему, присущую радиоприемным устройствам (РПУ) которые используют прямую оцифровку антенного входа с помощью высокочастотных АЦП:
Основным недостатком, ограничивающим широкое применение подобного типа РПУ, является невозможность обеспечения высоких уровней динамического диапазона по блокированию. Поскольку на входе АЦП отсутствует фильтрация, то АЦП соответственно не может выполнять оцифровку одновременно сигналов большого и малого уровня. В соответствие нормам ГОСТ радиоприемник должен обеспечивать уровень восприимчивости по блокированию не менее 126 дБ/мкВ для РПУ второго класса и 130 дБ/мкВ для РПУ первого класса. Очевидно, что существующие типы АЦП 14-16 бит не в состоянии обеспечить выполнение этого параметра.
Вот и все. АЦП принципиально напрочь убивает динамический диапазон, что создает уязвимость АФАР для постановки блокирующей помехи. Осталось только оценить степень ее реализуемости. Для этого нам надо оценить чувствительность T/R модуля в локаторе F-35, чтобы на основе этого значения рассчитать потребную мощность помехи и на каком расстоянии может располагаться ее источник.
Если вы найдете ошибку в нижеследующих расчетах, не стесняйтесь! Смело пишите замечания и предложения в комменты )
Энергетический бюджет радиолинии локатор -> цель -> локатор
Нас интересуют две величины:
- мощность отраженного от цели сигнала, для оценки потребной мощности джаммера;
- уровень сигнала на входе антенной системы локатора, для оценки наступления момента блокирования АЦП TRM.
В качестве исходных данных возьмем значения:
Pt = 20kW: мощность передатчика радиолокатора F-35;
λ = 3cm: длина волны для частоты 10ГГц;
Gt = 35dB: коэффициент усиления антенны радиолокатора на передачу, линейное значение: 3162;
R = 400km: дальность до цели;
σ = 3m2 : ЭПР цели.
Фактически, при построении бюджета мы поэтапно воспроизводим основное уравнение радиолокации. Причина, по которой мы его не используем — это необходимость в промежуточных данных и соответственно прозрачность в том, как они получены.
|
Начнем с самого начала — передатчика. Изотропный излучатель мощностью Pt создаст плотность мощности D на расстоянии R:
 [1] [1]
Такой излучатель будет светить во все стороны одинаково, на то он и изотропный. Конечно, для локатора это может быть неплохим качеством, вот только плотность мощности в заданном направлении будет весьма скромной.
Чтобы ее повысить, используем направленные свойства антенны с коэффициентом усиления Gt, тогда плотность излучаемой мощности [Вт/м2] составит:
 [2] [2]
Очевидно, что с ростом расстояния в знаменателе выражения плотность мощности будет падать, поскольку телесный угол ограниченный диаграммой направленности передающей антенны будет расширяться с ростом дальности.
При облучении цели нашим передатчиком мы будем принимать мощность, зависящую от геометрических размеров цели. Если цель для простоты изложения будем представлять как антенну, тогда принимаемая целью мощность Pr будет зависеть от эффективной площади этой антенны Ae:
 [3] [3]
В свою очередь, эффективная площадь напрямую связана с коэффициентом усиления приемной антенны (читай — цели):
 [4] [4]
Выполняя очередную подстановку из [4] в [3], получим значение для уровня принимаемого сигнала в простой радиолинии передающая антенна локатора -> цель:
}^2R^{2}}") [5] [5]
Пока все понятно с точки зрения физики за исключением того, как интерпретировать коэффициент усиления цели Gr.
|
Но мы не будем ломать над этим голову, поскольку этот параметр напрямую связан с показателем ЭПР цели σ соотношением
 [6] [6]
Если мы подставим это в предыдущее выражение [5], то получим значение мощности сигнала переотраженного от цели:
 [7] [7]
Индекс t2 теперь означает, что теперь это другое значение мощности передачи, на этот раз с какой интенсивностью цель светит обратно на локатор.
Теперь распространение пошло в обратном направлении — от цели к приемной антенне локатора, и для радиолинии цель -> приемная антенна локатора мы будем использовать точно такое же выражение [5]:
}^2R^{2}}") [8] [8]
Новые обозначения несут следующий смысл:
Pr2: мощность сигнала, принимаемого антенной радиолокатора;
Gr2: коэффициент усиления антенны радиолокатора на прием: очевидно, что он будет таким же, как и Gt. Позже мы вернемся к этому;
Pt3*Gr: мощность отраженного целью сигнала, которая на самом деле есть не что иное, как Pt2.
Подставляя значение Pt2 из [7] вместо произведения Pt3*Gr в [8], получаем:
}^2R^{2}}") [9] [9]
}^2R^{2}}") [10] [10]
и в результате мощность, принимаемая на выходе антенны радиолокатора, будет равна
}^3R^{4}}") [11] [11]
|
Я не случайно сделал оговорку: на выходе антенны, поскольку выход — это уже суммирование сигналов T/R элементов, а нас интересует как раз мощность на их входе. Но обо всем по порядку: каркас из формул мы создали, теперь начинаем считать.
Немного о смыслах: физических
Итоговые значения можно схематически представить в следующем виде:
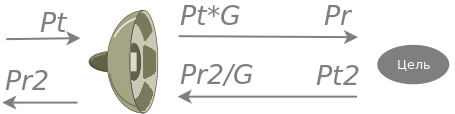 Передаваемые и принимаемые мощности в бюджете радиолинии локатора Мы можем сразу посчитать порядок значений мощности сигнала отраженного от цели Pt2 [7] для определения сопоставимой мощности, требуемой от источника помехи — джаммера. Что касается мощности Pr2, то это суммарная мощность, образуемая вкладом всех TRM антенны. Собственно в этом физический смысл коэффициента усиления антенны G: собирая сигналы со всех T/R модулей, повышается энергетическая эффективность в направлении синфазного сложения сигналов, то есть в направлении основного лепестка диаграммы. При этом несущественно, является ли антенна дискретной решеткой, как в нашем случае, или представляет собой непрерывную конструкцию, как например рефлекторы спутниковых антенн: все равно, или с физической, или математической точки зрения происходит суммирование (а точнее интегрирование) мощностей, принимаемых парциальными элементами площади рефлектора.
В результате, чтобы оценить мощность сигнала принимаемого каждым T/R модулем, нужно грубо говоря разделить выходную мощность антенны Pr2 на количество модулей, а точнее — убрать значение коэффициента усиления G из формулы [11]. Для сомневающихся предлагаю провести самостоятельный эксперимент: построить диаграмму направленности такой антенны из 1676 модулей и сопоставить площадь основного лепестка с уровнем побочных излучений. Получится тоже самое значение 35 дБ. Собственно говоря, это значение было так и получено.
Тогда уровень сигнала, отраженного от цели на входе TRM будет
}^3R^{4}}") [12] [12]
Вы заметили, как резко снизился порог воздействия на вход TRM — на целых G=35 дБ? Это то, о чем я говорил в начале статьи об особенностях АФАР.
Считаем
Наконец, после долгой возни с формулами, переходим к числам ). Подставляя исходные значения в [7] и [12], получаем:
мощность сигнала отраженного от цели Pt2=-10.2 dBm;
мощность сигнала на входе TRM Ptrm= -144.7 dBm.
Как чувствует себя локатор F-35 с такой не очень маленькой целью (ЭПР 3м2 это небольших размеров самолет) на расстоянии 400км? Абсолютное значение сигнала -144.7 dBm на входе TRM нужно соотнести с уровнем шума, чтобы делать выводы по отношению сигнал/шум. Для этого воспользуемся материалами по потерям в антенно-фидерном тракте бортового радиолокатора AN/APG-81 установленного на F-35.
По приведенным данным, с учетом потерь на распространение шумовая температура всего приемного тракта составит 996К. Это значение получено путем суммирования значений шумовой температуры антенны с учетом атмосферного шума (96К) и потерь в приемном фидере (98К). Шумовая температура приемника 608К получена из комнатной температуры (290К) с учетом коэффициента шума 4,91 дБ — столько вносит собственно приемник, или LNA входящий в состав TRM. С учетом потерь в приемном тракте 1,31 получается искомое значение 996К.
Умножая шумовую температуру на постоянную Больцмана, получаем шумовую плотность мощности, приведенную ко входу приемника 1.374*10-20 Вт/Гц. Это относительная величина, которая показывает мощность шума на единицу ширины спектра. Чтобы получить абсолютное значение шума — шумовую мощность, необходимо учесть ширину полосы принимаемого сигнала. С длительностью зондирующего имульса 1 мкс требуемая полоса пропускания составит около 1 МГц; таким образом будем ориентироваться на шумовую мощность 1.374*10-20 Вт/Гц * 106 Гц = 1.374*10-14 Вт, или -108.62 дБм (мощность в дБ относительно значения 1 мВт). Много это или мало? Предположим, что эта мощность приложена к стандартной нагрузке 50 Ом, тогда шумовое напряжение на входе приемника составит около 0.83 мкВ. Вполне реальное значение.
Таким образом, шумовое значение на входе T/R модуля радиолокатора AN-APG-81 составит минус 109 дБм. Отношение сигнал/шум составит -144.7 dBm — 109 dBm = -35.7 dB. Не очень здорово, скажем так, но не будем забывать что позади еще схема диаграммообразования антенны, в которой сигнал основного лепестка сложится синфазно, шум сложится кое-как, и в результате отношение сигнал/шум на выходе антенны будет -35.7 dB + 35 dB = -0.7 dB, что уже не так плохо.
Подчеркнем еще раз: при воздействии на вход T/R модуля радиолокатор с АФАР теряет преимущество в использовании коэффициента усиления антенны, что ни много ни мало 35 дБ.
Динамический диапазон 12-битного АЦП в составе TRM составляет 72.2 дБ. Предположим что коэффициент передачи усилителя LNA перед АЦП равен единице, поскольку его значение не влияет на физику блокирования АЦП — меняется только масштаб величин. Естественно, что АЦП будет работать при существенно более значимых входных сигналах, но для нас имеет значение только относительный расчет. Тогда диапазон входных сигналов, которые полностью займут разрядную сетку АЦП, составит от -144.7 dBm до -144.7 dBm + 72.2 dB = -72.5 dBm.
Чтобы стать самым сильным сигналом для АЦП (а это уже почти блокирование), постановщику помехи — джаммеру достаточно иметь мощность -10.2 dBm + 72.2 dB = 62 dBm, или 1.58 кВт. Таким образом, при мощности джаммера 1.58 кВт дальности 400км у радиолокатора F-35 оказывается под вопросом.
На самом деле, картинка несколько сложнее, поскольку мы имеем дело с импульсными сигналами, а значит они не обязательно должны перекрываться во времени. Если джаммер будет работать с duty circle 100%, то подавление будет полным, но этот режим требует больших энергоресурсов джаммера и не может использоваться в течение длительного времени.
Сделаем оценку того, какое воздействие окажет мощность помехи например 5 кВт, или 67 dBm. В этом случае эквивалентная минимальная величина отраженного от цели сигнала составит 67 dBm — 72.2 dB = -5.2 dBm. Такое значение соответствует дальности локатора около 225 км, при этом помеха точно также как и в предыдущем случае займет весь динамический диапазон АЦП, а полезный отраженный сигнал будет находиться на уровне одного бита.
В результате блокирования полезный сигнал будет потерян во всех TRM и формировать диаграмму уже не будет никакого смысла.
Заключение
В статье было исследовано влияние метода прямой оцифровки сигнала с антенного модуля АФАР радиолокатора AN/APG-81 истребителя-бомбардировщика F-35 и связанная с этим возможность блокирования АЦП модуля T/R. Получены оценки потребной мощности постановщика помех (джаммера), который находится на таком же расстоянии, как и цель локатора.
Значение пораженной дальности локатора AN/APG-81 составит 400км при мощности джаммера около 1.58 кВт и 225км при мощности джаммера около 5 кВт. При таком блокировании радиолокатор F-35 теряет возможности формирования диаграммы и подавления джаммера.
Данные приведены при непрерывном излучении джаммера, в импульсном режиме, когда отраженные от цели сигналы и помеха могут не перекрываться, степень подавления уменьшится.
Расчет произведен для 12-разрядных АЦП приемных модулей. С повышением разрядности эффективность подавления также уменьшится. Ее величину можно оценить пользуясь приведенным математическим аппаратом.
Для встраиваемых систем выбор кубиков, которые можно сложить во что-нибудь путное, не так уж и велик. То, что находится прямо перед глазами, не дает однозначного выбора.
ARM хорош и к тому же быстро развивается, сопроцессор с плавающей точкой NEON с распараллеливанием выполнения (pipeline) уже само собой разумеющийся атрибут. В последнее время обозначилась новая мода — использовать GPU для решения вычислительных задач, таких как FFT. Программировать под ARM — одно удовольствие, если пользоваться кросс-компилятором на собственной машине, среда Embedded Linux как правило привычна и дружественна разработчику. За все это заплачено отсутствием реального времени и возможностей обработки данных в синхронном режиме. Что же, для этого есть другие инструменты.
FPGA мыслится как первое что можно поставить скажем после АЦП. Синхронная обработка параллельных данных и возможность фильтрации на высокой частоте выборок (до 500 MS/s) определяют ПЛИС как стандарт де-факто на первом месте в сигнальном тракте. После фильтрации и децимации сигнал получается использовать как в DSP, так и в том же ARM. Конечно, с ПЛИС лучше работать не программисту (который может получить вывих мозга), а традиционному инженеру-схемотехнику. В конечном счете, FPGA есть не что иное как миллионы логических элементов, которые нужно просто соединить правильным образом.
Роль DSP также понятна: числодробилка с собственным pipeline, которая к тому же может принимать данные с синхронного интерфейса и вести обработку на несущей частоте. В современных процессорах операция FFT над выборкой 1К чисел с плавающей точкой занимает буквально несколько микросекунд. Сколько гребенок доплеровского фильтра можно сделать с таким процессором!
Рано или поздно кому-нибудь пришла бы в голову мысль скрестить между собой попарно эти кубики. В результате родилась архитектура Zynq, где возник симбиоз ARM + FPGA, и архитектура OMAP, основанная на ARM + DSP. Вот про вторую конфигурацию я бы хотел поговорить подробнее.
ARM+DSP или DSP+ARM?
Идея работать в дружественной среде Linux и одновременно получить те возможности, которые дает DSP, выглядит очень привлекательно. Для радиоинженера логичной бы выглядела связка DSP+ARM (именно в этой последовательности), в которой сигнал через физический интерфейс поступает в обработку DSP, в результате которой извлекаются информационные параметры сигнала, и ARM принимая эти полученные данные доделывает уже остальное: организует третичную обработку, отображение, управление и контроль.
Однако, все получилось немного не так. По замыслу разработчиков архитектуры OMAP, которая позиционируется как мультимедийная, DSP выступает в роли Accelerator Subsystem, фактически как сопроцессор-акселератор на подхвате у ARM. В принципе понятно, для чего это придумывалось: ARM получает данные с какой нибудь камеры, а DSP сопроцессор берет на себя критичные куски алгоритма, для которых требуется производительность. Но мы не привередливые: пусть будет ARM+DSP, где Linux на первой руке получает блоки данных, пусть и в асинхронном режиме, а условный доплеровский фильтр берет на себя DSP. На том и порешили, после двинемся дальше.
Codec Engine
Поскольку мы имеем представление, что будут делать ARM и DSP порознь, сосредоточимся на том, как они будут обмениваться данными. Хотя эти ядра и расположены на одном кристалле, но все таки это два совершенно разных процессора. Интуитивно понятно, как это может быть сделано: для этих процессоров существует некая общая область памяти, которую заполняет ARM и читает DSP и наоборот, если мы хотим сделать обмен данными двунаправленным. Ну и конечно должны быть библиотеки неких функций, которые можно дергать со стороны ARM, что проявится в виде неких сигналов в подсистеме DSP: данные мол готовы, забирайте.
Для тех, кто сталкивался с обеспечением подобного рода взаимодействия, а точнее — с разработкой протокола, известно с какой головной болью это связано. Поэтому благой вестью для нас является то, что компания Texas Instruments, разработчик SoC OMAP 3530, очень сильно постаралась не только для создания такого протокола, но пошла еще дальше — создала целый программный API под названием Codec Engine. Вот как эта структура выглядит на практике:
 Codec Engine: передача данных между ARM и DSP Codec Engine, или CE, берет на себя множество мелочей, в которых так легко сделать ошибку: выделение памяти под передаваемые данные как со стороны ARM, так и со стороны DSP, поддержку функций обмена, средства сборки проекта опять таки со стороны ARM Linux, так и со стороны SYS/BIOS DSP. Кроме этого библиотеки CE включают в себя средства отладки, что вообще замечательно в части DSP, потому как просто так в этот процессор не залезешь.
Механизм обмена между ядрами ARM и DSP я использовал в проекте пассивного радиолокатора, где DSP подсистема использовалась для тяжелонагруженного алгоритма нахождения функции неопределенности сигнала.
Ложка дегтя
Так и стали бы ARM с DSP жить и добра наживать, и потускнел бы заголовок нашей статьи — причем здесь горечь, видны только одни радости? Как обычно бывает, при погружении в каждую технологию начинают всплывать вещи, о которых вначале не подозреваешь. Ничего страшного конечно не происходит, но есть нюанс. Об этой ложке дегтя — далее.
Сам CE — достаточно тяжелое решение. То, что компилируется из исходников, у меня на машине состоит из 103599 файлов — ни много ни мало. Собственные приложения выглядят карликом на фоне этого монстра ) Проект был собран и запущен в работу, и все было ОК. Но как-то появилась необходимость опробовать новые приложения на ARM стороне, которые требовали версии ядра Linux постарше чем 2.16. В чем проблема, накатим новое ядро! И тут опс… Codec Engine не захотел собираться с новым ядром. В чем причина?
Как выяснилось, подсистема Линукс-ядра IOMMU, которая отвечает за отображение памяти на периферийные устройства и которую использует CE, существенно изменилась в версиях Linux старше 3.0.50. Почему именно этот номер версии — потому что это максимум, чего получилось достичь вместе с патчами ядра. Вот тут и обозначился проблемный аспект архитектуры OMAP: на апгрейд Linux на стороне ARM можно ставить крест. Нет, вы конечно можете использовать только ARM ядро, без DSP с любой версией Linux. Но тогда про DSP можно забыть.
Второе. Само собой разумеется, моим приложениям на ARM понадобилась поддержка операций с плавающей точкой, и я решил поставить дистрибутив с аппаратной поддержкой этих операций. И соответственно перекомпилировать CE с новыми библиотеками. И тут началось… как выяснилось Texas Instruments как бы это мягче сказать… не вполне наделил свои исходники возможностями брать конфигурацию с корневых make файлов. Я обнаружил кучу кода, который отказывался компилироваться просто по той причине, что он просто игнорировал замену конфигурации с arm-linux-gnueabi на arm-linux-gnueabihf. Приходилось править его вручную. Было заметно, что в дебрях ветвей CE находятся такие древние файлы, что похоже в TI могло не остаться людей которые могут подсказать что они там делают )
Так что будьте осторожны с такими комплексными архитектурами. После экспериментов со связкой ARM+DSP невольно стала напрашиваться мысль что лучше было бы сделать взаимодействие между ними на аппаратном уровне…
Что касается Zynq, то обмен между ARM и FPGA был выполнен на удивление просто: стандартными средствами Linux DMA через обычное устройство /dev/xdma. Простая поддержка файловых операций, не более того. Интересно, почему по этому пути не пошли Texas Instruments в Codec Engine?
 Одновременная трасляция видео на два экрана При проведении занятий и семинаров, да и при размещении нескольких экранов в больших залах возникает желание транслировать на них одну и ту же картинку. Конечно, для этого существуют готовые решения, но когда в загашнике есть Raspberry Pi, хочется побольше простору и гибкости. Поскольку для планирования трансляции можно написать какой угодно скрипт или даже программу, открываются следующие возможности:
- проигрывать плейлист по расписанию, в зависимости от времени дня и дня недели;
- делать рекламные вставки в паузах между видео, в том числе включающие трансляцию с собственных камер;
- автоматически менять программу в зависимости от посетителей;
- и многое, многое другое.
 Raspberry Pi с флешкой содержащей видеофильмы и разветвитель HDMI интерфейса. Свисток Wi-Fi используется только для управления RPi по сети Поскольку RPi содержит только один HDMI выход, нам понадобится разветвитель, или сплиттер. Я ограничился двумя выходами и установил коробочку, которую купил на AliExpress (хвала Поднебесной!). К коробочке не предъявляется никаких особенных требований, за исключением того что сплиттер должен быть активным, т.е. обеспечивать усиление сигнала для компенсации потерь при разветвлении.
Плюс к коробочке — два десятиметровых HDMI кабеля, которые будут подключаться к ТВ экранам. Любой из современных плоских ТВ сейчас имеет HDMI вход, так что с этим проблем нет.
Раздача сигнала по Wi-Fi представляется мне плохой идеей, поскольку во-первых требует от ТВ наличия Smart модуля, что удорожает девайс, а во-вторых — забивает локальную сеть непрерывно идущим видеотрафиком. Поэтому все делаем строго по кабелям.
С точки зрения общего замысла все это выглядит так. RPi проигрывает медиа-файлы, расположенные на флешке, и направляет поток на HDMI выход. К нему подключен сплиттер, который формирует два идентичных выходных потока из входного для двух экранов. Вот и все. Дальше — детали, связанные с тем как всем этим управлять, то есть плавно переходим к программной начинке RPi.
Настройка софта Raspberry Pi
Начнем сначала — с флешки. В качестве таковой используем накопитель на 64Гб, который отформатируем в NTFS:
|
|
user@ubuntu:~ $ sudo mkntfs -f -L MEDIA /dev/sdb1 |
Флешка на моей машине опознается как sdb1, не перепутайте со своим жестким диском!
Почему NTFS? Чтобы иметь возможность записывать фильмы большого размера (>4Гб) и чтобы иметь возможность использовать флешку отдельно вместе с ТВ, поскольку Linux-файловые системы телевизор не понимает.
Далее, дадим RPi возможность автоматически монтировать флешку на старте (поскольку она все время будет вставлена в разъем), для чего добавляем строчку в /etc/fstab:
|
|
/dev/sda1 /mnt ntfs defaults,ro,umask=022 0 0 |
На RPi флешка опознается уже как sda1: в общем, смотрите внимательно, чтобы не потерять свой основной накопитель. Здесь есть несколько нюансов: файловая система монтируется как доступная только для чтения (read only), ведь нам ничего не нужно записывать туда, верно? И это страхует нас от необходимости чистить файловую систему ntfs после отключений питания. И кроме этого задаем маску, которая позволяет читать файловую систему всем, иначе доступ к ней будет только из под root.
Уже в этой точке вы можете полюбоваться одновременной трансляцией на два экрана, запустив плеер:
|
|
pi@rpi:~ $ omxplayer /mnt/film.mkv |
Почему именно omxplayer? Потому что он использует API чипов RPi, которые содержат аппаратные кодеки видео. Поэтому медиа-трансляция не нагружает АРМ процессор — декодирование потока из h.264 выполняется аппаратным кодеком. Запустите на RPi top и увидите, что загрузка CPU редко превышает 30%.
Если вы запустите обычный плеер, то перегруз процессора за 100% при воспроизведении видео вам гарантирован.
Далее, нужно сделать процесс удобоваримым для участников, которые не разбираются в удаленном доступе через ssh и работой в командной строке. Для этого на компе администратора (Ubuntu) я сварганил следующий Питоновский скрипт.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
#!/usr/bin/python3 # -*- coding: utf-8 -*- from PyQt4.QtGui import * from PyQt4.QtCore import * import sys import os import time class myListWidget(QListWidget): def Clicked(self,item): cmd = "ssh -t pi@rpi.local pkill omxplayer" os.system(cmd) time.sleep(2) cmd = "nohup ssh -t pi@rpi.local /usr/bin/omxplayer /mnt/Films/%s > /dev/null 2> /dev/null &" % item.text() os.system(cmd) def main(): app = QApplication(sys.argv) listWidget = myListWidget() os.system('ssh -t pi@rpi.local "ls /mnt/Films" 1>/tmp/out.txt 2>/dev/null') string = open('/tmp/out.txt', 'r').read() #Resize width and height listWidget.resize(600,240) listWidget.addItems(string.split("\n")) listWidget.setWindowTitle('PyQT QListwidget Demo') listWidget.itemDoubleClicked.connect(listWidget.Clicked) listWidget.show() sys.exit(app.exec_()) if __name__ == '__main__': main() |
Скрипт показывает окошко на машине админа, в котором содержится список фильмов (точнее, видеофайлов). Двойным кликом на имени файла админ запускает трансляцию этого видео, после чего все могут смотреть кино сразу на двух экранах.
Чтобы скрипт работал, нужно обеспечить беспрепятственный доступ к RPi с машины админа, а именно — однократно запустить команду
|
|
user@ubuntu:~ $ ssh-copy-id rpi.local |
где rpi.local — адрес малышки RPi. В результате будут сформированы ключи и не нужно будет каждый раз вводить пароль при запуске скрипта.
При запуске скрипт заходит на RPi по ssh и командой ls /mnt формирует список видео, который сохраняется в локальном файле /tmp/out.txt. Мы же помним, что после автомонтирования на /mnt у нас теперь файловая система NFTS флешки? Далее, из этого файла формируется список, который выводится в окне.
При двойном клике на имени файла из списка, опять таки через ssh запускается omxplayer с заданным именем файла в качестве аргумента. Чтобы избежать повторных запусков разных видео, каждый раз перед запуском плеера все его процессы убиваются.
Если взять скрипт за основу, то можно делать все эти вещи, которые я привел в начале статьи. Да, и чуть не забыл: доступ к RPi обеспечивается через Wi-Fi свисток (донгл), который находится в локальной сети. Если назначение системы — просто непрерывно крутить плейлист, тогда и связь по Wi-Fi не нужна.
Когда будете воспроизводить систему, убедитесь в этом что источник питания RPi содержит достаточный запас по мощности: все таки два занятых USB порта и работающий Wi-Fi это хорошая нагрузка.
 Импортозамещение — эвфемизм, который на самом деле указывает на отсутствие собственных производственных возможностей. В области систем связи и радиоэлектроники переход на отечественную комплектацию и решения получился настолько болезненным, что многие фирмы изобрели ряд легких способов как продемонстрировать свою «импортозамещенность». Импортозамещение — эвфемизм, который на самом деле указывает на отсутствие собственных производственных возможностей. В области систем связи и радиоэлектроники переход на отечественную комплектацию и решения получился настолько болезненным, что многие фирмы изобрели ряд легких способов как продемонстрировать свою «импортозамещенность».
В немалой степени этому способствовала неразбериха в формулировках того, какая продукция может считаться отечественной или попросту говоря — собственной разработки. Интуитивно понятно, что помимо российской прописки предприятие должно вести разработку технических решений и программного обеспечения собственными силами. При этом фактор собственного производства не так важен, поскольку производить железо можно где угодно, а вот развивать продукт и создавать на его основе другие решения (создавать «потомство») можно только обладая интеллектуальным заделом и ноу-хау вплоть до таких важных вещей, как исходные коды программного обеспечения — ПО. Говоря другими словами, только живое дает потомство, а от клона потомства ждать нечего.
Часто встречаешься с абсолютизацией производства, которое приравнивается чуть ли не к характеристике высокого уровня технического развития. Если брать пример телефонов Apple, которые производят на китайских заводах, то точно также они могут изготавливаться на таиландских или индонезийских. Но ни один из этих заводов не в состоянии разработать следующую генерацию смартфона или по крайней мере ответить на один из множества подобных вопросов: например, как и почему выполнено согласование передающего, приемного модуля и антенны в смартфоне? Поэтому порой доходит до смешного: все хотят видеть огромные цеха со станками как признак продвинутого предприятия. И в то же время на этих станках делают старье, в котором уже никто не разбирается — как оно работает. С другой стороны команда разработчиков из 10 человек создает современные радиолокационные станции, которые изготавливаются по кооперации.
Соотношение возможности разработки и производства я описал в статье «Это действительно ваша разработка?», где дал определение «красной зоне» разработки и «зеленой зоне» производства.
Понятно, что есть проблемы в замещении критичных компонентов, таких например как высокопроизводительные АЦП LTC2174IUKG-14 американской компании Linear Technology, которые используются в отечественных системах посадки самолетов ILS. На подобные компоненты оформляется экспортная лицензия, которая должна быть одобрена Госдепартаментом США. В случае запрета на поставку можно обойтись микросхемами с характеристиками поскромнее за счет увеличения объема оборудования, снижения быстродействия и ухудшения качества изделия. Это не меняет общей картины, когда ты разрабатываешь ILS и понимаешь как должна работать эта система.
Другая ситуация возникает, когда в определенном направлении нет никакого задела (от слова «совсем») и на отечественный рынок представляют «цельнотянутое» с Запада изделие с собственными шильдиками и децималями на документации. Тут уже трудно говорить, что в таком продукте является отечественным и насколько его можно отнести к собственной разработке. Производить — да, сколько угодно, но с появлением любого запроса на дальнейшее развитие или модернизацию — увы… Как работает — понимаем только на уровне регулировки, исходных текстов ПО и алгоритмов нет, понимания замысла тоже нет. Тут и возникает понятие China Copy: клонирование чужих изделий на собственных производственных площадях под своим, отечественным именем. Вроде бы уже не перебитые шильдики на передних панелях и не замазанная англоязычная маркировка на платах — свои чертежи и децимальные номера в документации, все по ГОСТу. Но клон от этого не перестает быть таковым — он никогда не даст потомства.
Для оживления повествования проследим историю «импортозамещения» в одной из российских компаний. Для примера возьмем не самое сложное изделие: систему коммутации речевой связи (СКРС), с помощью которой диспетчеры аэропортов ведут радиообмен с пилотами воздушных судов.
Начнем с прелюдии, когда все было просто и понятно: купил на Западе, продал в России.
Прелюдия: поставки радиосредств Rohde&Schwarz серии 200
В начале 2000-х российская компания «Азимут» развернула процесс закупок радиостанций серии 200 фирмы Rohde&Schwarz с последующей перепродажей на российской территории. Поскольку импортное оборудование, по отечественным правилам, нельзя использовать для целей УВД, было принято простое решение: поменять передние панели немецких радиостанций на свои, на которых надписи были уже на русском языке, а вместо логотипа Rohde&Schwarz была нарисована синяя подкова Азимута. Можно сказать, что это было «импортозамещение» начальной, первой ступени, в самом примитивном варианте.
 Оригинальный трансивер XU250A немецкой компании Rohde&Schwarz серии 200, используемый для связи диспетчер — пилот в гражданской авиации (на верхнем снимке)
Внизу — «Импортозамещенный» приемопередатчик XU250A российской компании «Азимут». Передняя панель заменена на содержащую надписи на русском языке. Решетка громкоговорителя выполнена отверстиями в отличие от вырезов в оригнале для упрощения технологии изготовления панели.
Назначение приемопередатчика — работа в российских приемо-передающих центрах для обеспечения радиосвязи диспетчер — пилот Такое же превращение из немецких в российские претерпели модули радиостанции, такие как этот тестовый генератор.
По фотографиям видно, что с названием радиостанции решили не заморачиваться: как она называлась XU250A в оригинальном варианте, так и осталось. Такие же обозначения остались у модулей приемо — передатчика.
В остальном видно, что компоненты установленные на передней панели — переключатели, разъемы, индикаторы не заменялись. Само собой начинка радиостанции осталась оригинальная немецкая.
Немцы скрепя сердце терпели такое отношение к своему бренду в надежде, что на российской территории будет развернуто изготовление и поставка радиостанций Rohde&Scwarz. Однако сотрудничество не состоялось. И видимо именно по этой причине из нашего повествования выпадает СКРС / VCS-4G Rohde&Schwarz: если дилер не обеспечил поставки одного продукта, то скорее всего со вторым будет то же самое. Поэтому СКРС VCS-4G в дальнейшем уже не рассматривалась как потенциальный кандидат для перепродажи на территории РФ.
К этому моменту «импортозаместительная» схема уже была обкатана и получила свое развитие в попытках наладить партнерство (читай — закупки/продажи) с другими европейскими компаниями.
СКРС Schmid Telecom VCS 200/60
По мере развития отечественного рынка средств УВД заказчики начали соображать, что покупать импортное железо под отечественными шильдиками это в некотором роде контры с государственной политикой в этой отрасли, которая была направлена на поддержку «настоящих» отечественных производителей. Поскольку разрабатывать свое хлопотно и дорого, и хочется быстро и выгодно продавать западную, было придумано «импортозамещение» второй ступени.
Его особенность заключалась в том, что народ начал все меньше интересоваться содержимым плат и узлов и гораздо больше — программным обеспечением. И также вопросами, кому это ПО принадлежит и кто владеет исходными текстами.
Для наглядности я сделал подробную диаграмму, в которой присутствует красная зона — интеллектуальная область разработчика, и зеленая зона — то чем располагает завод. В очередной попытке перепродажи западной СКРС нужно было показать заказчику, что помимо зеленой зоны отечественный поставщик также контролирует красную зону, если попросту — располагает исходными текстами ПО. И такая возможность представилась с известной фирмой Schmid Telecom, Швейцария.
 СКРС VCS 200/60 Shmid Telecom Эта швейцарская компания — признанный лидер на европейском рынке СКРС. И конечно, она была заинтересована в продвижении своей продукции — СКРС VCS 200/60 на объемный российский рынок. Переговоры шли на высокой ноте, под хрустальный звон бокалов с шампанским и соблазнительной перспективой создания совместного предприятия. Блестки и конфетти мешали руководству конторы вникнуть в смысл лицензионного соглашения, где в разделе Software прописывают условия поставки ПО. В сущности, в подобных документах пишут вполне очевидные вещи, как например:
The Installation Package includes all SW and FW Module Versions that build together a certified SW Release.
Пакет установки включает все Software и Firmware модули, которые собраны в один программный релиз.
Все ясно — это пакет инсталляции ПО, поэтому речь идет о бинарных модулях (зеленая зона). Ну и немного лирики на тему того, что для аборигенов этого вполне достаточно 🙂
The VCS SW and FW are highly configurable. Any dimensioning of the system extension, every kind of functional parameters settings, Touch screen HMI and roles definitions do not require any modification of the SW or FW.
Through a very comfortable Configuration program an authorised user is enabled to define and download all the characteristics of the system. To partially or completely rearrange the operator interfaces HMI.
Due to this enormous flexibility, the need to extension and modification of the running SW and FW is very improbable.
Краткий перевод выглядит следующим:
Программное обеспечение СКРС отлично конфигурируется. Любое изменение параметров не требует какой-либо модификации софта.
Посредством весьма удобной программы конфигурации можно задать все характеристики системы, частично или полностью изменить пользовательский интерфейс.
Благодаря высокой гибкости, потребность в расширении возможностей или модификации работающего ПО представляется невероятной.
Вот она, игла Кощея: расширение возможностей и модификация работающего ПО. Внимание, красная зона, вход посторонним воспрещен! Если очень нужно, берите инструменты для конфигурации софта, меняйте как хотите картинки на дисплее, но технологии мы вам не дадим — расширять возможности и модифицировать ПО вы не будете. И это правильно: в программном обеспечении сидит вся капитализация Schmid Telecom: вся история развития, ошибки, неудачи и находки, конкурентные преимущества, методы реализации требуемых параметров.
Насколько разработчики Schmid Telecom представляют ценность для компании, демонстрирует следующий пример. Если заказчику нужна доработка системы, которая требует участия программистов, какой бы высокой не была оплата этой опции, программистов на ее реализацию никто отвлекать не будет. Подобные решения принимаются на самом высоком уровне — совете директоров. Если доработка будет признана целесообразной, она будет включена в RoadMap для последующего воплощения. Вот такая мощная башня из слоновой кости.
Желание поскорее двинуть швейцарский продукт под своим шильдиком было настолько велико, что на выставке МАКС 2011 оборудование Shmid Telecom чуть было не «импортозаместили» на ходу путем использования технологии Azimutation Kit: клей, ножницы, бумага 🙂 Благо, на серии 200 все было обкатано, а для выставки пойдет просто поменять фирменные логотипы.
К этому моменту контора сообразила, что без того чтобы продемонстрировать интеллектуальную собственность красной зоны, включая исходные коды ПО, не получится убедить заказчиков, что это самый натуральный российский продукт в стиле «сделаноунас». Но была проблема. С одной стороны, Шмид ни под каким соусом не соглашался показывать свою исходную программную документацию, с другой — ее все таки надо было демонстрировать проверяющим и сертифицирующим инстанциям. В результате интеллектуальных брифингов родилась схема с легким налетом романтики аферистического толка. Она заслуживает того, чтобы продемонстрировать ее 🙂
В представлении интеллектуалов конторы все должно было выглядеть так. Центральную часть схемы занимает сейф. В этот сейф Шмид приносит исходные тексты ПО и никому не показывая, запирает его на свой ключ. Поскольку владелец ключа ни в коем разе не должен выглядеть европейцем, который разговаривает на немецком (документация-то типа отечественная!), ключ вручается под расписку местному товарищу. В расписке указано что партнер, то есть контора ни одним глазом не может заглянуть в доки — они демонстрируются только проверяющим от государства. Далее в игру должен вступить некий проверяющий и сертифицирующий субъект, которого провожают в комнату с сейфом и он, небрежно пролистывая несколько сотен страниц с распечатками, говорит: йес! верую, что это ваше! Поскольку на сейфе и на каждой странице будет надпечатан логотип конторы.
Гениально, правда? Только почему-то не заработало. Может, проверяющие товарищи не хотели слишком сильно пачкаться, или были другие причины — перспектива убедить соответствующие органы в том что «красная зона» — наша, начала таять.
Когда наконец пришло осознание того, что технологии красной зоны никто отдавать не собирается и от аборигенов требуется только клепать железо в стиле China Copy без подтверждения права на собственный софт, поднялся шум. В результате, как и с Rohde&Schwarz, проект приказал долго жить.
СКРС Sitti «Multiphono»
Следующим партнером, которого можно было приспособить на российской территории под российским брендом, планировалась миланская компания Sitti. Вообще список разработчиков СКРС не так уж и велик — не считая Sitti, осталось рассматривать только австрийскйю компанию Frequentis. Подробный обзор по Sitti у меня есть в отдельной статье, здесь я только дополню этот технический обзор краткой историей о том, как проходила попытка «импортозамещения» уже с этой компанией.
Итальянцы были жизнерадостны и обаятельны: продавать систему — пожалуйста, производить на территории России под брендом партнера — можно подумать, но передавать технологию, то есть исходные коды программ — no, è impossibile. До конторы начало доходить, что все готовы поделиться (естественно не безвозмездно) своим урожаем, но продавать поле с которого ты кормишься (красная зона) никто не собирается. Никто и никогда не продает свои технологии, и в самом деле, для этого надо быть самоубийцей, чтобы добровольно отдать свой бизнес другому.
Контора сделала последнюю попытку: предолжила Sitti продаться целиком вместе с СКРС. По идее это должно было выглядеть круто, а на самом деле было жалко и смешно. Итальянцы вежливо посмеялись, помахали ручкой и уехали в Милан. На этом все закончилось.
Самое обидное для конторы было то, что технологии отказался продавать даже отечественный разработчик СКРС — небольшая зеленоградская компания 🙂
СКРС собственной разработки
Да-да, такое тоже случилось однажды. Когда продукта для перепродажи нет, в голову приходят невеселые мысли о собственной разработке. Невеселые — потому что своих специалистов нет, а если даже их набирать — плохо вписывается разработка в торгово — закупочную парадигму. Все равно что на автобазе выделить площади для центра высокой моды 🙂
Если сами не умеем, можно заказать у тех кто умеет. Была найдена небольшая компания, продвинутая в разработке VoIP решений — имменно в этом изюминка проекта, поскольку требования Евроконтроля к СКРС описывают именно современные, VoIP решения. И все может быть и состоялось, но концу проекта, когда надо было принять работающую систему у подрядчика, нарисовалась еще одна торгово — закупочная возможность: перепродать СКРС Frequentis VCS3020X.
СКРС Frequentis VCS3020X
Соблазн был слишком велик: с одной стороны, собственная разработка, которую надо сопровождать и развивать, а с другой — готовое решение, которое нужно только грамотно перепродать на территории РФ. И начиная с этого момента судьба собственной разработки была решена: контора начала судебную тяжбу за проект, которая закончилась не в пользу разработчика VoIP СКРС (ну этому удивляться не приходится, зная как работает отечественная судебная система).
 Frequentis VCS3020X. Будущее российской импортозамещенной СКРС И старая торгово-закупочная машина, заправленная новым топливом, завертелась снова. Австрийская компания Frequentis является разработчиком СКРС и точно также как и предыдущие фирмы, начинает штурмовать аэродромные просторы РФ. Вполне возможно, что отечественные диспетчеры получат неплохую западную систему VCS3020X, разработанную в 2004 году, пусть даже и с перебитыми шильдиками и переделанной документацией. Только логотип у фирмы размашистый, придется перекрывать его тоже чем — нибудь значимым 🙂
Остались только вопросы, правда они носят скорее риторический характер.
Вопросы напоследок
Зачем делать вид, что в критичном аэродромном оборудовании используются отечественные системы и компоненты? Переделка документации и производство, призванные скрыть оригинального производителя, за которым все равно остаются чужие технологии и программное обеспечение (красная зона), ведут только к удорожанию и невозможности дальнейшего самостоятельного развития направления.
Почему бы просто не пустить на отечественный рынок такие компании как Thales, Rohde&Schwarz, тот же Frequentis со своей VCS3020X? Конечно, после этого сразу прекратят свое существование торгово — закупочные конторы, занимающиеся «отмывкой» западного оборудования, но зато возникнет внутренний рынок для специалистов, в том числе разработчиков.
Есть еще один аспект, связанный с внедрением пресловутых «закладок» в Firmware чипсетов и ПО. И если для радиолокатора или пеленгатора, использующего импортные компоненты, трудно представить как может быть активирована эта закладка, то для связного и коммуникационного оборудования, каким является СКРС, сам бог велел. Не имея исходных кодов ПО и Firmware «красной зоны», вы не найдете эту закладку. Активировать ее можно множеством способов: звонок в систему с определенного номера, специально сконструированные кодовые конструкции в цифровом трафике RTP, команды в протоколах сигнализации, связанных с внешними телефонными системами. Возможностей огромное количество, и странно наблюдать спокойствие служб, которые обычно сильно заморочены на шпионских сюжетах в то время как под девизом «прибыль любой ценой» идет затаскивание троянского коня.
Да и в любой момент австрийцам из Frequentis могут напомнить про санкции и озвучат предложение, от которого невозможно отказаться. После этого хайтек оборудование «отечественного производителя» станет просто кирпичами.
Ну а пока лучшие представители российских фирм успешно демонстрируют на форумах и выставках свои China Copy под шумные аплодисменты ничего не подозревающих зрителей и участников 🙂
|
|



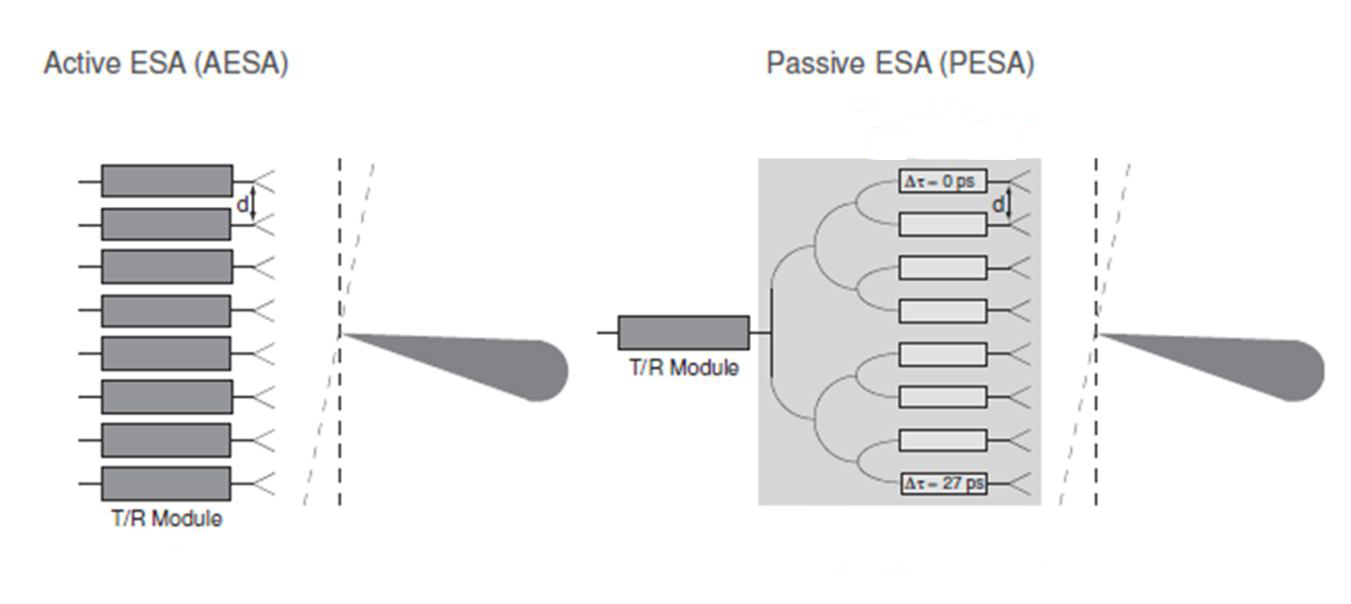




Last comments