В применении к задачам пассивной радиолокации, в конечном счете двумерное изображение радиолокационной обстановки формируется с помощью кросс — функции неопределенности (ФН):
(1)
Приставка «кросс» означает, что в отличие от классической ФН одного сигнала, выражение содержит взаимную функцию неопределенности сигнала s(Δt, Δf), переотраженного от цели с приобретенной задержкой Δt и доплеровским сдвигом частоты Δf, и опорного сигнала r(), формируемого местным радиоокружением (базовой станцией).
Каким образом посчитать это выражение? Существует два подхода к этой задаче; они определяются тем, каким образом мы представляем физический смысл этого соотношения. Рассмотрим два варианта группировки элементов выражения (1) — A и B, которая отражает наше представление о том, каким образом производится обработка сигналов:
План A: перебор в частотной области
Начнем с представления A. В этом представлении, помеченным синим цветом, формула представляет собой в чистом виде запись корреляционной функции двух сигналов. Первый сигнал — это сигнал цели s(), сдвинутый по частоте на величину f с помощью экспоненциального множителя. Второй сигнал — комплексно-сопряженный опорный r().
Тогда алгоритм нахождения двумерной кросс-ФН получается таким: для каждой частоты f находим корреляционную функцию сигнала цели, смещенного на частоту f, и опорного сигнала. Набор таких корреляционных функций в пространстве частот f составит 2D пространство кросс-ФН.
Поскольку наш алгоритм рано или поздно заземлится на определенной аппаратной платформе, что предусматривает наличие эффективного вычислителя БПФ, будем искать корреляционные функции не в лоб, а с использованием преобразования Фурье. Псевдокод на Питоне/numpy, соответствующий сценарию A, будет выглядеть следующим образом:
Python
1
2
3
4
5
6
7
8
9
10
REF=np.fft.fft(ref)
# F: пространство частот
# t: пространство отметок времени
f=0
forfreq inF:
exf=np.exp(1j*2.*np.pi*freq*t)
rot=sig*exf
product=np.fft.fft(rot)*np.conj(REF)
am[:,f]=np.fft.ifft(product)
f=f+1
БПФ для опорного сигнала ref вычисляется только один раз, поскольку он не меняется по ходу действа. Сдвинутый по частоте сигнал rot подвергается преобразованию Фурье и перемножается с комплексно — сопряженным БПФ опорного сигнала. Корреляционная функция находится как обратное БПФ этого произведения.
Не считая однократного БПФ опорного сигнала, в этом варианте мы должны выполнить БПФ в количестве, соответствующем количеству доплеровских частот, которые представляют для нас интерес. Плюс столько же обратных преобразований Фурье (многовато получается, однако).
В результате, матрица af будет содержать набор корреляционных функций для каждой частоты f, то есть кросс — функцию неопределенности. Данный метод можно назвать методом с перебором в частотной области.
План B: перебор во временной области
У нас в запасе есть еще план B, отмеченный красным цветом. При такой группировке произведение s()r() выглядит как самостоятельная функция, и тогда все выражение до боли напоминает преобразование Фурье от этой функции. Да что там напоминает — так оно и есть. Мы должны выполнить столько БПФ, сколько временных задержек сигнала мы собираемся рассматривать. При этом никакого обратного БПФ выполнять не нужно.
Алгоритм на псевдокоде будет использовать перебор во временной области:
Python
1
2
3
4
#T: пространство отметок времени
fortinrange(T):
mul=sig*np.conj(ref)
af[:,t]=np.fft.fft(mul)
В данном сценарии, БПФ используется столько раз, сколько используется временных задержек сигнала, представляющих интерес.
A vs B
С точки зрения быстродействия сценарий B выглядит поинтереснее, хотя с точки зрения физического смысла выполняемой обработки сигнала он не такой прозрачный, как сценарий A. Мы упустили из виду еще один существенный фактор, влияющий на время выполнения: размер выборки для операции БПФ.
Для плана A размер выборки — это длительность сигнала на временной оси, для плана B — пространство наблюдаемых доплеровских сдвигов частоты. Соотношение размеров этих выборок будет определяться тем, какие диапазоны дальности и скорости целей будут представлять для нас интерес, а какие необходимо будет исключить.
И в этой ситуации сопоставление эффективности этих сценариев становится не таким простым делом…
Не так давно случилось событие, которое вернуло мой интерес к малютке Raspberry Pi. Были открыты спецификации чипа GPU, в результате чего была реализована идея выполнить быстрое преобразование Фурье (FFT) на видеопроцессоре. В результате народ написал тестовый код, и быстродействие по сравнению с выполнением на ARM возросло в 10 раз. Очень даже неплохо! Для тестирования 2D FFT, что нужно для функции неопределенности, я решил заранее подготовиться и оборудовать рабочее место. Об этом данный пост.
Donwload
Для загрузки берем минимальный дистрибутив Raspibian Jessie Lite, что означает что мы добровольно отказываемся от графики на RPi. Да и зачем она нужна?
Дальше все по инструкции, распаковываем образ и копируем его на SD карту.
Я сразу сделал еще одну вещь: вызвал GParted и раздвинул второй раздел до конца флешки. Если этого не сделать, моя 16 Гб SD карта выглядела как маленькая 2-х гигабайтная.
Поскольку я использую с RPi WiFi свисток, или донгл, пока еще SD карта в компьютере, сразу настроим беспроводную сеть в файле /etc/wpa_supplicant/wpa_supplicant.conf
Мы не будем подключать к RPi клавиатуру и монитор: работаем только удаленно. Можно было бы уже извлечь SD и воткнуть ее в RPi. Несмотря на то, что сеть поднимется, нас ждет засада: сейчас по умолчанию ssh на плате не работает, поэтому к ней не доступиться.
Поэтому не будем торопиться и выполняем workaround: создаем в разделе boot пустой файл ssh. Это сигнал загрузчику, что нужно запустить сервер ssh при загрузке.
Теперь отмонтируем карту, вставляем в RPi, включаем питание и заходим по ssh. IP адрес или имя можно найти на WiFi маршрутизаторе.
Следующие шаги
Быстро пробежимся по тому что надо сделать сразу на будущее.
1. Чтобы не вводить каждый раз пароль для ssh: ssh-copy-id pi@raspberry.local
2. raspi-config: устанавливаем локаль, часовой пояс, включаем ssh на постоянно.
3. apt-get update, apt-get upgrade: обновляем систему, при этом подтянется firmware. Теперь уже не обязательно запускать rpi-update как раньше.
4. Ставим apt-get install vim, делаем его удобоваримым корректируя /etc/vim/vimrc:
Shell
1
2
3
syntax on
set shiftwidth=4
set tabstop=4
5. Позаботимся о Питоне:
Shell
1
2
3
apt-getinstall python3
apt-getinstall python3-numpy
apt-getinstall python3-scipy
Пока все. Дальше, чтобы каждый раз не ждать сборки проекта на RPi (все будет очень медленно) и не мучить флешку, настроим кросс — компиляцию. Компилировать будем на моей машине под Ubuntu. Чтобы не гонять файлы на RPi и обратно, поднимем каталог под NFS и сделаем его доступным со стороны RPi по сети. Тогда вся работа, а именно редактирование и сборка перемещаются на хост машину. Запускать надо будет только на самой RPi.
Поднимаем NFS
Делаем на host — компьютере, т.е. на моей машине под Ubuntu:
Здесь /home/user/rpi/public это директория, которую мы открываем для внешнего доступа. В этой директории и будем дальше копаться с кросс — компиляцией.
Перезапускаем NFS подсистему /etc/init.d/nfs-kernel-server reload. Как видите, я со стартовыми скриптами по старинке. NFS сервер готов.
Делаем на target — компьютере, т.е. на Raspberry Pi:
myhost.local: имя хост — компьютера, который у нас под Ubuntu;
/home/user/rpi/public: директория на хост — компьютере, которую мы будем видеть, само собой она должна быть точно такой же, как прописано на host компьютере;
/home/pi/cross: директория на RPi, которую надо создать.
Теперь все что мы будем творить на хост машине в директории /home/user/rpi/public, будет видно на целевой машине — RPi в директории /home/pi/cross. Сразу уточню для ясности: если отключить хост — машину, то директорая /home/pi/cross на целевой машине окажется пустой.
Перегружаем RPi, чтобы произошло автоматическое монтирование этой директории.
Кросс — компиляция
Для кросс — компиляции нужен компилятор, который будет создавать исполняемые файлы в формате архитектуры armhf (процессор ARM, реализация плавающей запятой — аппаратная). И не только компилятор: компоновщик, архиватор библиотек и прочие инструменты.
Кроме этого, нужна специальная ветка h — файлов и библиотек, также заточенная под armhf — так называемый toolchain. Вручную ворочать этими ветками с длинными названиями тяжело, поэтому пойдем простым путем. Не помню откуда, но у меня на хост — компе живет директория arm-bcm2708. Это как раз инструменты для RPi, которые я скачал в незапамятные времена. Из под этой директории отрастают ветки, в которых и будет копаться компилятор — ему виднее, где что лежит. Все инструменты и toolchain там уже есть. Надо только грамотно подключить все это к нашему проекту.
Для этого берем и делаем унифицированный makefile:
# ключи для подключения библиотек (может они вам и не нужны, но что будут подтянуты
# именно armhf библиотеки, продемонстрировать не мешает)
F=-lrt-ldl-lm
all:hello
hello:$(S)$(C)$(H)
$(CC)-ohello$(F)$(C)
clean:
rm-fhello
Все, что вам нужно поправить под себя в этом файле — это первая строчка. В результате делаем make — и скомпилируется программа hello, состоящая из исходников hello.c и hello.h.
После сборки hello тут же появится в директории /home/pi/cross.
Еще раз, чтобы не путаться: редактируем файлы и делаем make на host машине (ради этого все и затевалось с кросс — компиляцией и доступом по NFS), запускаем — на target машине. Если вы попытаетесь запустить исполняемый файл архитектуры ARM на Intel машине, получите сообщение об ошибке:
Взаимодействие компонентов JTRS. Как все красиво выглядело вначале
Программа JTRS — Joint Tactical Radio System должна была увязать сетью цифровой радиосвязи все виды и рода вооруженных сил США. Радиостанции, выполненные по технологии SDR, могли быть выполнены в носимом и возимом варианте; предусматривалось применение как в сухопутных войсках, так и в ВВС и ВМФ.
Программа стартовала в 1997 году, на НИОКР было выделено 6 млрд. долларов. После того как деньги были израсходованы, программа была закрыта. После этого была попытка оживить JTRS, которая опять-таки закончилась очередным закрытием в 2012 году.
И как это бывает в затянувшихся проектах, пока все ожидали результатов JTRS, военное ведомство США тем временем было вынуждено приобретать обычные средства связи, что вылилось в дополнительные 11 млрд. долл. Само собой, после появления в войсках радиостанций JTRS эти вновь купленные средства связи должны были быть списаны.
Таким образом, в результате 15 лет, потраченных впустую и минус 17 млрд. долларов. Что пошло не так?
Какая связь нужна
Совершенно очевидно, что на поле боя без связи — никуда. Перед глазами сразу появляются картинки из советских фильмов, когда связист накручивает индуктор телефона ТА-57 и кричит в трубку под грохот разрывов: «Тополь, тополь, я береза, дайте огня по высоте безымянной!». Только в современности двусторонняя связь отходит в прошлое. Появилось модное слово — сетецентричность, хотя зачем выдумывать новые сущности? И так ясно, что это должна быть сеть связи, поверх которой работают системы боевого управления.
Эти системы, при том же количестве ресурсов — танков, артиллерии, беспилотников, авиации и так далее — позволяют достичь двукратного преимущества за счет только информационного обмена, координации и управления. Пример: локатор на соседней позиции засекает разведывательный БЛА противника и определяет его координаты. Координатная информация тут же идет командиру подразделения, над которым завис беспилотник — вплоть до трека реального времени на командирском планшете. Командир дает команду другому узлу визуально опознать БЛА, после чего получает на свой планшет возможную классификацию БЛА и его фото. После этого идет запрос к серверу баз данных, в результате чего командир получает информацию по боевым и разведывательным возможностям беспилотника. Весь этот блок данных — тип БЛА, его местоположение в реальном времени и его ТТХ — идет в вышестоящий узел сети для принятия решения. Если принимается решение поразить цель, то аналогично данные идут зенитному расчету.
Очевидно, что наладить подобное взаимодействие без помощи развитых средств связи немыслимо. И такие средства связи предполагалось создать с помощью JTRS. Большим подспорьем в этом проекте явилась технология Software Define Radio, SDR. С помощью нее все проблемы формирования излучаемого сигнала — частоты, мощности, модуляции уходили в программную область компьютера радиостанции. Так же и по отношению к радиоприему: большая часть тракта обработки принимаемого сигнала — демодуляция, декодирование, передача данных и голоса — теперь также приходилась на программную область. И этот подход до сих пор оправдал себя на практике вплоть до наших дней: любой мобильник представляет из себя SDR устройство. Чего же не хватило программе JTRS для того, чтобы быть успешной?
Евангелие от создателя продукта
Ключевая особенность JTRS заключалась в том, радиостанции создавались как программируемые устройства с возможностью дальнейшего апгрейда и развития софта, а также чтобы создавать новые приложения, которые могут стать необходимыми в будущем. Для того, чтобы разрабатывать ПО для каждого из вида радиосигналов (waveforms), требуется участие квалифицированных инженеров / программистов третьих сторон, то есть из команд, которые не являются частью больших компаний — исполнителей проекта. Необходимость подобного привлечения уже никто не оспаривает после того как военные обожглись на создании своей собственной операционной системы: задача по написанию и отладке более 15 миллионов строк кода (значение приведено для версии ядра Linux от 4.0) оказалась неподъемной ни за какие деньги, и поэтому с тех пор используются ОС, которые разрабатываются на коммерческом и открытом рынке.
Поскольку военные люди все делают по приказу, то по причине того, что некому было отдать такой приказ, или командиры не потрудились изучить, каким образом успешные бизнесы привлекают к своим проектам профессионалов, это направление было упущено. В подобных разработках притически важно создать успешный тренд, который будет развиваться самостоятельно (поддерживать тренды, в которых никто не хочет участвовать, не хватит никаких сил и денег).
Особенность самоподдерживающегося тренда состоит в том, что участники или вкладываются в успешный тренд и количество их увеличивается, либо они спрыгивают с тонущего корабля. Это хорошо понимали в таких компаниях как Microsoft и Apple, где для создания позитивного самоподдерживающегося тренда работают специальные люди — «евангелисты». Евангелист сосредотачивается на том, чтобы привлечь сторонних разработчиков программного обеспечения, чьи ранние инвестиции (личным ресурсом) в инструменты, повторно используемые компоненты и приложения имеют решающее значение для запуска тренда. Если завоевать симпатии комьюнити не получится, то дальше идти бесполезно: продукт умрет.
В программе JTRS не было своих евангелистов, чтобы вовлечь в разработку специалистов, которые работают за пределами военной области в обширном гражданском коммерческом секторе. JTRS соответствовала стилю разработки программного обеспечения и жизненным циклам системы, распространенным в сугубо военных приложениях, но которые не подходят для более широкого коммерческого применения.
В недрах программы JTRS была рождена стандартная программная платформа: Software Communications Architecture (SCA), которой должны были соответствовать все программные разработки. В результате между идеологией этой платформы и стилем разработки, принятым на открытом рынке возникли непримиримые противоречия, которые приведены в этой таблице:
JTRS — типичная разработка для военных с соответствующим подходом
Характерные особенности программы JTRS
Подходы в военной области
Подходы на коммерческом рынке
Стандартная платформа
Заказывается централизованно, ограниченный объем поставок регулируется также централизованно
Выбирается владельцами бизнеса на основе признанных стандартов и протоколов, объем поставок большой
«Военный» процесс разработки
Большие команды разработки
Высокий порог вхождения: дороговизна инструментов разработки
Фокус на соответствие требованиям и правильность
Небольшие гибкие команды
Малые вложения в инструменты разработки, как правило бесплатные лицензии
Фокус на сокращение времени выхода продукта на рынок
«Военный» жизненный цикл изделия
Длительный жизненный цикл
Стоимость сопровождения превышает стоимость разработки
Короткий жизненный цикл
Стоимость разработки и производства преобладают
Создатели RCA определили жизненный цикл SDR радиосредств, созданных на ее основе — 10 лет. Это значит они заглянули на 10 лет вперед и решили, что военные радиостанции будут современными и актуальными и в конце этого срока. Между тем, когда начиналась разработка JTRS, не было таких технологий как WiFi, 3G и 4G, и потоковая передача видео через Интернет. Лучшие военные умы создавали каналы цифровой связи скоростью аж 9600 бод. За это время жизнь ушла далеко вперед: WiFi стал массовым, народ смотрит потоковое видео с разрешением HD, что раньше нельзя было себе представить (и все это без технических заданий), а JTRS с добротными ТЗ осталась далеко позади.
Платформа RCA оказалась настолько сложной, что отпугнула многих внешних разработчиков ПО, которые могли бы создавать приложения для нее (вместо самоподдерживающегося тренда военные просто отпихнули чужих специалистов). Далее, RCA использовала древнюю технологию обмена данными Corba, что предполагает наличие программного интерфейсного модуля Corba в каждом сменном блоке. Это не проблема для тех блоков которые содержат процессор, под который разработка ПО ведется на языке высокого уровня. Однако, для ПЛИС, а также подобных низкоуровневых устройств, имеющих весьма специфическую архитектуру и систему команд, поддержка стека протокола Corba оказалось сложной и насла дополнительные накладные расходы, связанные со сложностью разработки и потерей быстродействия при передаче данных.
В результате, платформа RCA так и не смогла преодолеть круг разработчиков военного ведомства, и задача привлечения квалифицированных сторонних разработчиков ПО так и не была выполнена.
В этом программа JTRS полностью повторила ошибки военных по созданию языка программирования Ада, когда ограничение доступа к разработке приложений на новом языке привело к тому, что программисты переключились на другие, более доступные языки, и специалистов по Ада сейчас — кот наплакал.
Вы видели блоки в мобильнике?
Типичная сборка Ground Mobile Radio: набор блоков соединенных шиной SCA
На физическом уровне платформа RCA обеспечивает взаимодействие унифицированных модулей, которые могут заменяться в полевых условиях. Каждый конструктив имеет как минимум один процессорный модуль. Для ручных радиостанций использовался точно такой же подход, несмотря на то что модули жестко интегрированы в трубку и не подлежат оперативной замене. Это было вызвано необходимостью повторного использования ПО, которое было разработано для реально заменяемых модулей.
Как мы сейчас уже знаем, в противоположность такому подходу в коммерческих радио-продуктах используются чипы с высокой степенью интеграции, что исключает необходимость механической компоновки узлов и использования шины обмена (RCA), что связано с дополнительными потерями по быстродействию. В рамках коммерческого подхода радиочастотный модуль объединяется с преобразователями АЦП/ЦАП (аналоговый чип), в то время как в цифровом чипе совместно работают процессор общего применения и DSP/FPGA. Так например выполнена архитектура OMAP процессоров Texas Instruments.
Несмотря на то, что эти структуры обладают малой масштабируемостью, они используют эффективные платформы разработки и располагаются в существенно менее габаритном форм-факторе и цены на такие интегрированные компоненты существенно ниже. Поэтому в современном мобильном телефоне вы никогда не увидите такие блоки — они располагаются внутри чипа.
В результате архитектура JTRS была не только сориентирована на узкий круг специализированных исполнителей, но также и не использовала распространенные COTS решения огромного коммерческого рынка приложений, по причине своей жесткости. В результате открытый рынок, использующий собственные рентабельные стандарты, ушел далеко вперед (а что не уйти, если все деньги и лучшие специалисты — на этом рынке?)
И это все только на этапе разработки. На этапе обслуживания и сопровождения закрытые решения также обещали лечь тяжелым бременем на эксплуатацию.
Идея о том, что многообразие передаваемых и принимаемых сигналов — waveforms будет поддерживаться в программной области, а оборудование будет стандартизированным и его номенклатура будет ограниченной, вначале выглядела прекрасной. Далее, однако, выяснилось, что радиостанция — это все-таки инженерный, а не программисткий продукт. Программные модули для разных типов FPGA не получилось использовать за счет условной компиляции — для каждого типа ПЛИС пришлось писать свой код. Радиотракты (как и антенны) были сильно зависимы от диапазона и ломали архитектуру оборудования, а следом — соответственно начинала плыть архитектура ПО.
Кроме этого, одной из проблем JTRS было то, что войска нуждались в цифровой (новой) и аналоговой (для совместимости с унаследованным парком оборудования) связи в одной коробке. Данный фактор также препятствовал созданию полностью унифицированных модулей. Технические проблемы нарастали, и к ним еще начали добавляться сложности в управлении этим проектом, а также стало очевидным, что сами концептуальные основы JTRS начали подвергаться сомнению.
Кризис концепции и методологии — больше чем технические проблемы
Как вам нравятся предсказатели будущего, которые знают, каким будет мир через 10 лет, какое к этому времени будет железо, софт и технологии? Куда пойдет вектор развития? Вы представляете это ТЗ, которое рассчитано на 10 лет вперед?
Ладно, техническое задание — это конкретика. Поговорим о более философских вещах — концептуальных основах проекта. На концепции, как на фундаменте, стоят архитектуры, протоколы и технические решения JTRS. Одним из краеугольных камней программы было положение о том, что меняя программное обеспечение в FPGA, можно сократить номенклатуру плат и достичь реализации всего многообразия waveforms. Намек понятен: железо дорого и хлопот с ним много, его надо производить, поддерживать и ремонтировать, а софт — штука простая, один раз написал и прошивай все подряд.
Не знаю, были ли знакомы авторы программы JTRS с законом Мура, но они просто обязаны были предположить, что так будет не всегда. Сейчас стоимость аппаратных компонентов снижается с настолько драматичной скоростью, что гораздо проще и дешевле было бы иметь специализированные, заточненные под одну waveforms / вид сигнала платы, которые можно было паковать вместе, и не иметь никакого громоздкого унифицированного железа.
Методология исполнения JTRS как проекта также была раскритикована и названа главной причиной провала. Хотя проект развивался вполне в соответствии с принятыми в то время правилами Waterfall, или как сейчас его называют традиционной разработки (это то, как привыкли работать у нас и работают до сих пор). Идея методологии Waterfall (посмотрите на картинку и поймете почему это называется водопадом) очень проста: все необходимые действия надо выполнять последовательно.
В программе JTRS подобных блоков и субблоков было конечно гораздо больше, чем на картинке.
Традиционная методология разработки Waterfall. Проект движется, мир меняется
Я не исключаю, что именно после провалов проектов подобных JTRS, начался принципиальный пересмотр методов управления проектом, в результате чего возникли итеративные подходы к разработке.
Принципиальный недостаток подобной последовательной схемы можно продемонстрировать только одним фактом: в течение 13 лет разработчики последовательно выполняли программу, закрывая один этап и открывая другой, и в результате образцы радиостанций попали в войска, на тестирование конечным пользователям только в 2010 году.
Вдумайтесь! Тринадцать лет те, которым предстояло эксплуатировать эти радиостанции, не имели возможность высказаться и повлиять на процесс разработки. И когда тринадцать лет спустя в войсках увидели эти результаты, новые современные радиостанции JTRS получили нелицеприятную оценку «radio that weighed as much as a drill sergeant, took too long to set up, failed frequently, and didn’t have enough range»(радио весит столько же, сколько мой сержант-инструктор, слишком долго настраивается, часто отказывает и не дает дальности, которая нужна).
Что у нас?
Конечно, все что было сказано про боевое управление и связь относится также и к отечественным реалиям. Хронология получилась такая: в конце 2012 года появилось сообщение о том, что в войска начнут массово поступать цифровые радиостанции VI поколения «Азарт — П1». Конечно, нумерация поколений впечатляет, или может они ведут свое начало с искровых передатчиков?
Процесс появления новой радиостанции вызвал бурное обсуждение в комьюнити. Далее, в новости этого года было сказано, что радиостанции «Р-187П1 удалось не просто догнать, но и по некоторым позициям превзойти зарубежные образцы». Видимо, речь идет о той же радиостанции в портативном исполнении; в сети информация по возимому варианту отсутствует. В этой же новости было сказано, что радиостанция уязвима к средствам РЭБ и что к 2021 году будет производиться «сверхзащищенная» ее версия. Что-то мне подсказывает, что дополнительных версий будет еще много…
Конечно же, эта радиостанция — сетецентричная. Опять таки, нет данных, как реализована сетевая функция и какие waveforms используются. Вот тут, в наших реалиях точно нет никаких евангелистов и самоподдерживающихся трендов. Пирожок маленький, а желающих много: на всех не хватит.
Судя по всему, работы продолжаются, хотя очевидно и не с таким размахом как JTRS. Будем надеяться, что отечественные разработчики сделали выводы по результатам этой программы. В свое время было много отсылок на JTRS, типа «вот у американцев целый сетевой проект», потом отклики поутихли.
Промежуточный этап работы подсистемы обнаружения и сопровождения взлетно — посадочной полосы (ВПП). Для беспилотного аппарата (БЛА), или дрона, с учетом чувствительности к действию ветра, критически важно отрабатывать отклонения от глиссады. Для этого нужна автоматизированная система посадки, которая работает в реальном времени: оператор просто может не успеть.
В левом фрейме обычное видео из интернета, иллюстрирующее посадку борта на ВПП. Качество исходного видео это конечно не HD камера беспилотника, но оно и к лучшему: есть хороший запас по надежности распознавания. Дополнительный вклад в ухудшение качества видео внесла функция захвата видео с экрана для сохранения в клипе.
На видео наложены результаты работы алгоритма оконтуривания, причем красный цвет — контуры которые по мнению фильтра не соответствуют ВПП, синий — приблизительно напоминают ВПП.
«Приблизительно» означает, что мы сохраняем высокий уровень ложной тревоги обнаружения, чтобы сохранить снизить вероятность пропуска. Вероятность ложной тревоги снижается в результате более жесткого алгоритма, результат работы которого — на правом фрейме. Тут все немного сложнее.
Начнем по порядку. Каждый опознанный контур приводится к характерной точке ландшафта — Featured Point (FP). Эти точки проявляют тенденцию к относительно стабильному существованию во времени; ну и само собой они могут смещаться относительно камеры в зависимости от маневров БЛА. В этом собственно и содержится главная информация: динамика изменения положения FP относительно камеры.
FP на правом фрейме выглядят как зеленые кружки. Они чем-то напоминают радиолокационные отметки, или плоты, причем это сходство очень показательно: на самом деле, FP, или плоты, идут далее в траекторную обработку, как это происходит и в радиолокаторе. В отличие от радиолокации, здесь наблюдаем принципиально другую ситуацию: в трекинге участвуют плоты, положение которых взаимокоррелировано. Соответственно, в результате такой мультитрекинговой обработки формируются маркерные линии, которые соответствуют наблюдаемому положению ВПП.
Зеленый цвет переходит в желтый при потере трека. С этим алгоритмом больше всего работы; сейчас запущена первая версия.
Из видео хорошо видно, что плоты обладают гораздо более высокой динамикой, чем маркерные линии. Это объясняются тем, что линии формируются в процессе фильтрации с подавлением высоких частот, параллельно выполняя задачу усреднения выборок для уменьшения среднеквадратической ошибки позиционирования. В результате, маркерные линии формируют обрамляющий прямоугольник, положение которого во фрейме показывает отклонение БЛА.
Софт сделан на Python’е. Тесты показывают, что основная нагрузка на процессор возникает в алгоритмах оконтуривания. Предстоит соображать, как все это переносить на встраиваемую платформу…
В технологиях нейроподобных сетей (НПС) делаются определенные предположения о том, как кодируются сигналы, циркулирующие внутри НПС. При этом почему-то предполагается, что природа будет использовать аналоговые сигналы в том виде, к которым мы привыкли, и есть даже попытки «натянуть» наши компьютерные бинарные представления на НПС.
Как же на самом деле кодируются сигналы в реальной нейронной сети — в головном мозгу животного или человека, и как их можно интерпретировать? В последнее время появились очень интересные биологические исследования работы нейронов. В них авторы рассматривают проблему в основном под биологическим углом зрения, что соответствует их специализации. Поскольку мы инженеры, нам в свою очередь весьма интересны методы, которые природа выбрала для кодирования сигналов. И как обычно, очень хочется задать главный вопрос, на который кроме разработчика ответить некому: не только узнать, как сделано, а получить ответ на вопрос: почему сделано именно так?
Жаль, что этот вопрос повисает в воздухе. Поэтому посмотрим, до чего докопались неугомонные биологи, и воспользуемся результатами их трудов.
Результаты современных исследований
В этой обширной обобщенной статье Neural population coding: combining insights from microscopic and mass signals, которая в свою очередь использует результаты 119 научных работ в этой области, подведены промежуточные итоги исследований сигналов нейронных сетей. Картинку я взял тоже оттуда. Статья датирована мартом 2015 года.
Посмотрим на все это с точки зрения кодирования и обработки сигналов.
Реакция нейронов на различные символы. Картинка из статьи Neural population coding: combining insights from microscopic and mass signals
Не будем сильно углубляться в биологическую специфику методики экспериментов. Нас интересуют наблюдения и результаты.
На картинке приведена реакция четырех разных нейронов, обозначенных как A, B, C, D, на визуальные образы фигурок, различающиеся между собой формой. Очевидно, что эти нейроны определенным образом реагируют на форму изображений. На самом деле конечно были отобраны нейроны различных типов с данным видом реакции, которых может быть множество.
Давайте сразу начнем сомневаться: почему собственно для исследований наблюдались всего несколько нейронов. Насколько эти данные могут характеризовать поведение оставшихся? Этот подход оправдан, потому что как я скажу дальше, наблюдается большая корреляция между выходными сигналами множества нейронов в такой группе. Да, мы будем по привычке использовать понятие «выходной сигнал» нейрона. Биологи называют его spike — импульс, а группу называют популяцией нейронов. Поэтому поведение одного отобранного нейрона хорошо характеризует целую группу.
Следующее сомнение — почему импульсы обозначены черточками с равновеликой амплитудой? Мы можем согласиться с тем, что ширина импульса не критична, но амплитуда, один из важных информационных параметров? Есть такая гипотеза: природа полностью забила на амплитуду. Это объяснимо, потому что в этой электрохимической системе трудно поддерживать правильные уровни сигналов. К тому же индивидуум может закинуть себе в пасть нечто, что полностью перемешает все уровни сигналов в мозгу )
Важен только факт импульса и его положение на оси времени. И очень сильно похоже на то, что когда надо передать информацию об амплитуде, или интенсивности, или получить сигнал с большим весом — природа просто использует шину с одновременно передаваемыми импульсами. И правильно, что там мудрить с обработкой уровней сигнала — можно использовать или прорастить еще несколько проводов — вообще не проблема.
Это уже очень сильно отличается от технических представлений НПС, где амплитуда является информационным параметром. Собственно, именно по этому мы заместили амплитудную информацию образом сигнала в нашей НПС для пассивного радиолокатора.
Теперь снова взглянем на картинку.
Информационные параметры сигнала
Для того, чтобы передавать информацию посредством импульсов — spikes, необходимо использовать модуляцию параметров сигнала. Наблюдаем следующие методы кодирования параметров модуляции (перевод терминов мой, более близкий к инженерной области чем к биологической):
Firing Rate (темп выдачи сигнала). Количество, или интенсивность выходных импульсов определяет, на какую картинку реагирует нейрон. Нейрон A имеет «узкую настройку» и поэтому реагирует только на ромбик. Настройка нейронов C и D «шире» и больше предпочитают другие символы, а на ромбик реагируют вяло. Нейрон D вообще не дает никакой полезной информации и просто тупо реагирует на все картинки (может это стробирующий импульс?).
Relative Timing (взаимная задержка). Как видно по картинке, хотя нейроны B и C реагируют как на квадратик, так и на звездочку одинаковым количеством импульсов, для звездочки нейрон C дает задержку по времени. Чем не фазовая импульсная модуляция?
Periods of Silence (нулевой уровень). Отсутствие информации — тоже информация. Своим молчанием нейрон A говорит о том, что ромбик в поле зрения отсутствует.
Как видно из картинки, нет четкой закономерности в различении сигналов: может быть использован любой информационный параметр. Теперь посмотрим на другие трюки Природы, которые используются для дополнительного кодирования сигналов.
Комплементарность
Нейроны могут нести дополнительную, или комплементарную информацию по отношению к другим нейронам. В этом случае они увеличивают выходной сигнал (Firing Rate) когда наблюдают «свою» картинку, но также обладают способностью уменьшать его, когда вместе со своей картинкой присутствуют другие. Для чего это нужно?
Положим, каждый нейрон специализируется в узком диапазоне изображений, или на каком-нибудь одном сигнале. Тогда для того чтобы разделить большое количество разных сигналов, различающихся по определенному параметру, потребуется пропорциональный рост нейронов, каждый из которых будет иметь соответствующие «настройки». Голова будет большой что не очень здорово ) Но можно поступить по другому: настройки нейронов могут быть перекрывающимися и захватывать несколько сходных картинок, а комплементарная информация которую несут другие нейроны, будет способствовать лучшему за счет подавления «чужих» данных.
Межнейронная корреляция Firing Rate
Выходные сигналы нейронов могут обнаруживать связь между собой. Рассматривают два различных типа такой связи:
по отношению к различным входным сигналам, в этом случае корреляция говорит о различии в настройках нейронов на эти сигналы;
корреляция шума на выходе различных нейронов, когда на входе присутствует один и тот же сигнал.
С шумом вообще интересная история. Нейронная сеть мозга постоянно «шумит», то есть в отсутствие внешней информации по ней постоянно гуляют какие-то псевдослучайные сигналы. Для чего они нужны, пока не очень ясно. Однако, если на входе нескольких нейронов — один и тот же сигнал, а на выходе коррелированный шум — это уже о чем-то говорит. Вроде бы нейроны формируют случайные процессы, но по отношению к единому входному сигналу эти случайные процессы являются зависимыми, или грубо говоря подобными.
Такая своеобразная модуляция параметров выходного шума входным сигналом дала повод предположить, что это отдельный способ кодирования, дополнительный по отношению к Firing Rates. Почему бы и нет? В конце концов, нам известны такие шумоподобные сигналы, которые модулируются полезной информацией — например, CDMA. Шум шумом, но за счет кодового разделения можно вытащить информацию, которая требуется.
Есть версия, что различные значения корреляции для наблюдаемых объектов в динамике могут говорить о том, реагируют ли нейроны на один объект или на несколько различных объектов. Фактически, это еще один информационный параметр кодирования, обусловленный группировкой объектов. Есть еще одна версия, в которой различия в корреляции больших групп нейронов может говорить о том, как эти группы кодируют свою информацию. А это уже метаданные.
Тайная школа нейронных наук
В любом исследовании биологов на тему нейронных сетей ускользает один и тот же вопрос: каким способом эта сеть была обучена, выращена, создана и так далее. Очевидно, что множество функций было получено в процессе обучения сети. А это значит, что существует некий арбитр, который говорит сети об правильных распознаваниях сигналов и об ошибках, и в соответствии с этим меняет ее структуру и характеристики. По крайней мере так работает алгоритм Backpropagation в машинном обучении. В результате тренировки сети, которая идет от входных сигналов к выходным, формируются корректирующие сигналы, которые идут в обратном направлении — от выхода сети ко входу (отсюда и название алгоритма — обратное распространение).
Только вот беда, сколько специалисты не старались, они не нашли в живой природе сигналов, которые идут в обратном направлении. Да и структура нейронов, дендридов, аксонов и прочих кирпичиков этой сети для этого совсем не предназначена. Вперед, и только вперед — никаких обратных дорог.
Еще одна загадка: как нейронная сеть узнает о том, что она работает правильно, и меняет свой алгоритм в зависимости от обнаруженных ошибок? Может, когда мы обнаруживаем, что сделали что-то не то и в ответ бьем себя по лбу, это и есть та обратная связь которой недостает? ))
Видео советую смотреть в разрешении 720p или 1080p
Беспилотная тема выходит из лаборатории на свежий воздух. В результате кооперации с энтузиастами летающих моделей состоялся летный эксперимент — своего рода разведка боем. Он преследовал сразу несколько целей:
получение качественного видео, имитирующего взлетно — посадочную полосу (ВПП) с расположенными на ней маркерами. В качестве ВПП была отснята автострада;
проход над «ВПП» под различными углами, высотами и имитация захода на посадку;
получение данные телеметрии и создание подсистема их визуализации в реальном времени.
Все это — для дальнейшей обработки автопилотом оптической посадки, что и является основной целью данного проекта.
Результаты обработки эксперимента были сведены в два клипа длительностью около одной минуты. На первом клипе — данные с камеры, на втором — показания приборной панели, полученные по результатам телеметрии. Клипы были синхронизированы по времени, насколько это возможно.
Итак, рассказываю про эксперимент, что и как )
Борт
В качестве беспилотника взяли имеющийся в наличии Phantom 4. Это квадрокоптер, которому автоматическая посадка особо не нужна. Но мы все равно решили полетать на нем, чтобы иметь возможность сделать несколько проходов и обеспечить качество картинки. Фантом управлялся с отдельного пульта, к которому был подключен планшет Samsung/Android.
Когда дело дойдет до автоматической посадки, будем облетывать свое. Например это:
Иди даже вот это:
Энтузиасты свое дело знают!
Камера
На Фантоме установлена камера Go Pro с разрешением HD. Камера стабилизирована на карданном подвесе, есть возможность управления углом наклона. Мы выставили около 30° вниз, чтобы лучше было видно дорогу с маркерами.
Видео с камеры идет на экран приложения планшета, и также записывается приложением в формате mp4 целым файлом. Видео также записывается на SD карту которая вставляется в квадрокоптер, на карте я обнаружил несколько MOV файлов с размером около 2 Гб каждый.
Тут возникла первая проблема: частота фреймов Go Pro — 120 кадров в секунду, мои кодеки на Ubuntu неправильно определяли ее (как 30 fps) и соответственно попытка понизить frame rate до 30 кадров в секунду не увенчалась успехом. Потом я нашел другой способ: в видеоредакторе kdenlive использовал фильтр, который понижает скорость воспроизведения в четыре раза. В конечном счете, я просто взял mp4 файл который записался в планшете и работал с ним.
Вторая проблема касается синхронизации видео и телеметрии. В определенный момент соответствие картинки и данных компаса и высотомера расходились. Я предполагаю, что оператор Фантома не включал соответствующие режимы записи видео или телеметрии на некоторых взлетах/посадках. Это предположение основывается на том, что суммарная длительность видео и время лога телеметрии различались в полтора раза. Этот вопрос предстоит изучить более детально.
Софт
На планшет я установил приложение DJI Go, в котором можно получать изображение с камеры квадрокоптера. Покопавшись в файловой системе, нашел лог телеметрии. Его формат неизвестен, но есть возможность перекодировки в csv. Для парсинга лога я воспользовался сервисом сайта healthydrones.com.
Были оставлены только данные, которые представляют интерес: координаты в виде широта/долгота, данные компаса, высоты, угол наклона камеры и метки времени. Лог выглядел примерно так:
Лог телеметрии БПЛА
Как я уже говорил, в определенный момент произошла рассинхронизация лога телеметрии и видео. Поэтому клип в начале статьи имеет небольшую продолжительность, когда эти данные соответствуют друг другу.
Для обработки лога и визуализации полета «по приборам» было написано Qt приложение, которое разбирало лог синхронно с временными метками и отображало информацию на «приборах» кокпита. В качестве таких приборов были применены замечательные виджеты QFlightInstruments.
Индикация организована следующим образом. Данные высоты не калибровались. Они отображаются на отдельном индикаторе и на комбинированном индикаторе авиагоризонта.
Поскольку камера стабилизирована, горизонт показывает фактически не положение квадракоптера, а угол наклона камеры. На авиагоризонте также отображается компас, и он дублируется на отдельном индикаторе.
Фиолетовые линии крест — накрест используются нестандартным образом. На них я вывел информацию о местоположении относительно точки взлета. В процессе полета видно, как меняется позиционирование квадрокоптера по широте и долготе.
В правом верхнем углу — отметка даты и времени.
На панели есть еще один индикатор, который пока не используется. На него будет выводится посадочная информация — отклонение БПЛА от глиссады. Это позволит оператору вести посадку как в ручном режиме, так и контролировать посадочный автопилот.
ToDo
Дальше — прогон видео через алгоритм распознавания изображений, в том числе маркеров ВПП, и через трекер. Предстоит выбрать аппаратную платформу, которая будет летать на борту, и набор сенсоров. И конечно сделать соответствующую авиамодель, которая сейчас находится в работе.
Задачи распознавания изображений обладают интересным свойством. Вот смотришь на картинку и видишь прямую, которая образована разбросанными точками. Как только пытаешься получить эту прямую по данным точек в программе — сразу возникают алгоритмические трудности.
Что поделаешь, это еще одно напоминание о том, что человеческий глаз — это совершенное средство обработки данных.
В этом примере прямая — это некоторая закономерность, которую нужно найти в потоке данных. Где может пригодиться такой алгоритм? Например, в распознавании маркеров взлетно — посадочной полосы оптической системы посадки БПЛА. Или хотя бы определить направление, в котором дедушка Ляо идет из кабачка домой.
Следы оставленные дедушкой Ляо по дороге из кабачка домой
Понаблюдаем же за дедушкой Ляо. Хорошо посидев с друзьями своей юности в кабачке, он спешит к домашнему очагу. Как видно из карты перемещений, у дедушки Ляо не очень уверенная походка. Тем не менее, очевидно что он стойко идет к своей цели. Очевидно для нас, потому что мы пользуемся совершенными инструментами — собственными глазами. А что делать компьютеру? Как ему выявить закономерность на основе данных десяти точек?
Для этого можно использовать понятие собственных чисел и собственных векторов матрицы. Поскольку теорию мало кто любит и тем более мало кто запоминает, рассмотрим эти понятия на простом примере и затем вернемся к дедушке Ляо во всеоружии.
Матрицы линейного преобразования: портим фигуру
По старой доброй традиции, воспользуемся богатыми математическими возможностями Питона. Не мудрствуя лукаво, нарисуем следующую фигурку — двойной ромбик:
Python
1
2
tst=np.mat([[-3,-2,-2,-1,-1,0,0,1,1,2,2,3],
[0,-1,2,-2,4,-3,6,-2,4,-1,2,0]])
Для наглядности можно вывести значение этой матрицы на экран:
Python
1
2
[[-3-2-2-1-10011223]
[0-12-24-36-24-120]]
Матрица определяет фигурку из 12 точек, первая строка — x координаты точек, вторая строка — y координаты. Выглядит фигурка так:
Фигурка, соответствующая исходной матрице
На этом с исходными данными все. Теперь начинается самое интересное: мы будем портить нашу фигурку. Для этого матрицу фигурки умножаем на матрицу линейного преобразования A, которая может растягивать фигурку по горизонтали:
Python
1
A=np.mat([[2,0],[0,1]])
Или сжимать также по горизонтали:
Python
1
A=np.mat([[0.5,0],[0,1]])
Растягивать по вертикали:
Python
1
A=np.mat([[1,0],[0,2]])
Перекос:
Python
1
A=np.mat([[1,1],[0,1]])
Мы можем даже повернуть фигурку, например на 30° по часовой стрелке. Как вы догадываетесь по значению элементов матрицы линейного преобразования, не обошлось без синусов и косинусов соответствующего угла поворота:
Python
1
2
3
A=
[[0.870.5]
[-0.50.87]]
Или вообще вместе со сжатием и растяжением еще перекосить ее так, что сразу и не узнаешь:
Python
1
A=np.mat([[1.2,0.5],[0.2,1.2]])
Воспользуемся последним преобразованием и скособочим нашу фигурку:
Матрица линейного преобразования A перевела 12 наших исходных векторов на другие позиции, то есть поменяла их координаты: на то оно и преобразование.
Однако, существуют такие векторы, которые напрочь отказываются преобразовываться. При попытке матрицы линейного преобразования сжать их, растянуть, перекосить или повернуть они переходят сами в себя. Для каждого линейного преобразования эти векторы свои, поэтому они называются собственными векторами матрицы. Есть еще и собственные числа, которые участвуют во всем этом следующим образом: эффект от линейного преобразования собственного вектора такой же, как будто бы его просто умножили на собственное число. Проще говоря, собственное число — просто масштабирующий множитель. Матрице конечно обидно, что она ничего не может сделать с собственным вектором и ее многомерный эффект преобразования сводится к простому умножению на число. Но что поделать!
Вскрытие собственников
Найдем собственные числа и собственные векторы нашей матрицы преобразования A. На Питоне это делается одной строчкой:
Python
1
w,v=np.linalg.eig(A)
Я придерживаюсь обозначений, которые показаны в примерах модуля numpy Питона: w — это собственное число, v — собственный вектор. Неудобно, что слова vector и value начинаются на одну и ту же букву, и поскольку вектор главнее, собственное число получило наименование w.
Посмотрим что получилось:
Python
1
2
3
4
5
6
7
8
A=
[[1.20.5]
[0.21.2]]
v=
[[0.85-0.85]
[0.530.53]]
w=
[1.520.88]
Очевидно, что для нашей матрицы линейного преобразования существуют два собственных вектора и два собственных числа.
Первая парочка:
Shell
1
2
3
4
5
v1=
[[0.85]
[0.53]]
w1=
1.52
Наступил момент истины. Подвергнем вектор линейному преобразованию:
Shell
1
2
3
4
5
6
A*v1=
[[1.28]
[0.81]]
w1*v1=
[[1.28]
[0.81]]
Так оно и есть: собственный вектор «не чувствует» родную матрицу A и остается таким же, как и был, точнее — умноженным на собственное число.
Проверка второй парочки:
Shell
1
2
3
4
5
6
7
8
9
10
11
12
v2=
[[-0.85]
[0.53]]
w2=
0.88
A*v2=
[[-0.75]
[0.47]]
w2*v2=
[[-0.75]
[0.47]]
Тоже самое: какого-либо желания трансформироваться не обнаружено напрочь.
Principal Component Analysis (PCA), или Метод главных компонент в поисках закономерностей
Теперь мы хорошо подготовлены к тому, чтобы переварить идею метода PCA, вынесенного в заголовок. Метод основан на поиске осей максимальных изменений входных данных; эти оси называются компонентами, что и послужило основой для названия метода. Подробное и самое главное — понятное описание метода для химических приложений изложено здесь (вспоминая замечательный журнал Химия и жизнь).
На самом деле, кроме поиска закономерностей, метод выполняет еще одну задачу: отделяет существенные данные от несущественных; и кроме этого обладает еще одним важным свойством, о котором я скажу в конце. Применив этот метод, мы наконец узнаем, каков на самом деле был кратчайший маршрут дедушки Ляо и что считать его действительным направлением движения, а что — отклонениями (эх, дедушка Ляо, если бы ты меньше просиживал в кабачке то не пришлось бы связываться с отклонениями!).
Мы неспроста тренировались на собственных векторах и числах, поскольку они являются основой для реализации метода PCA (есть и другие реализации). Если мы поняли это, то до понимания реализации метода остался только один шаг. Этот шаг — использование матрицы линейного преобразования как ковариационной матрицы выходных данных.
Итак, начнем с выборки следов дедушки Ляо, которую для солидности будем именовать треком из 10 точек:
Shell
1
2
3
track=
[[2.40.72.92.23.2.71.61.11.60.9]
[2.50.52.21.93.12.32.1.1.51.1]]
Уберем из трека постоянную составляющую и найдем ковариационную матрицу трека:
Shell
1
2
3
np.cov(track)=
[[0.7170.615]
[0.6150.617]]
Сделаем передышку и осмыслим сделанное (физический смысл — основа любого метода). О чем говорит ковариацонная матрица? Одинаковые значения 0.615 говорят о степени связи (корреляции) переменных x[0..9] и y[0..9], которые являются соответствующими координатами трека (простите, в Питоне индексы начинаются с нуля). Элементы главной диагонали 0.717 и 0.617 говорят о корреляции этих переменных с собой же, то есть это практически значения мощности, если переменные интерпретировать как сигналы.
Поэкспериментируем с ковариационной матрицей на более простых данных. Будем брать значение ковариации слегка зашумленных отрезков из трех точек.
Диагональный отрезок под 45°:
Shell
1
2
3
np.cov([1,1.9,3.1],[0.9,2.1,2.9])
array([[1.11,1.04],
[1.04,1.01]])
Диагональный отрезок под -45°:
Shell
1
2
3
np.cov([1,1.9,3.1],[-0.9,-2.1,-2.9])
array([[1.11,-1.04],
[-1.04,1.01]])
Вертикальный отрезок:
Shell
1
2
3
np.cov([0,-0.1,0.1],[0.9,2.1,2.9])
array([[0.01,0.04],
[0.04,1.01]])
Горизонтальный отрезок:
Shell
1
2
3
np.cov([0.9,2.1,2.9],[0,-0.1,0.1])
array([[1.01,0.04],
[0.04,0.01]])
Как видно по результатам, ковариационная матрица чувствительна к углу поворота отрезка. Она определяет степень разброса данных и их ориентацию в пространстве. Теперь, основываясь на этой матрице, было бы хорошо найти вектор, который смотрит в сторону наибольшего разброса. Этот вектор на самом деле тот самый компонент метода PCA, который нам нужен.
Если мы еще раз нырнем в теорию, то обнаружим, что искомые векторы на самом деле являются собственными векторами ковариационной матрицы.
# убираем постоянную составляющую, или среднее значение
A=track.T
M=(A-np.mean(A.T,axis=1)).T
# находим собственные числа и векторы ковариационной матрицы
[evalue,evector]=np.linalg.eig(np.cov(M))
# а это уже что-то новое
rotated_track=np.dot(evector.T,M)
Осталось запечатлеть результат работы на картинке. Красным цветом представлены собственные векторы ковариационной матрицы, которые и есть главные компоненты, или оси максимальной изменчивости данных.
Главные компоненты метода PCA. Справа — трек в новой системе координат (rotated_track)
На картинке справа — тот же самый трек в новой системе координат, или проще говоря повернутый на угол одной из осей главных компонент (еще одна причина того, для чего ее нужно было искать). Такое преобразование выполняет последняя строка фрагмента программы:
Shell
1
rotated_track=np.dot(evector.T,M)
Кажется, подошло время к тому, чтобы сделать кое-какие выводы.
Тайное становится явным
«Человек, у которого только одни часы, точно знает который час. Обладатель двух часов ни в чем не уверен»
До сих пор все шло прекрасно. Ведь согласитесь, что мы в глубине души ожидали, что метод главных компонент подтвердит нашу не очень глубокую догадку о том, что трек дедушки Ляо проходит по оси юго-запад — северо восток. Так оно и есть. Но есть и вторая компонента, которая упрямо доказывает нам, что дедушка Ляо вполне мог двигать и по оси северо-запад — юго восток. И действительно, если ассортимент кабачка оказался забористым, герой нашего рассказа продвигался очень медленно, зато качало его из стороны в сторону будь здоров. Конечно, коротенький второй вектор говорит о том, что это направление как-бы не главное, но оно есть.
Теперь дальше. Мы действительно выделили закономерность во входном треке. Можем даже предположить, что главная компонента это и есть трек, искаженный шумом. Таким образом, мы разделили существенные и несущественные данные. И самое интересное, мы переместили трек в новую систему координат, вследствие чего он стал одномерным (говоря по научному, мы выполнили ортогонализацию). Понижение размерности входных данных — это большое достижение, например, для этого предназначены такие сложные итерационные методы, как преобразование Грама — Шмидта.
И в конце вишенка на торте. Посчитаем ковариационную матрицу повернутого трека:
Python
1
2
3
np.cov(rotated_track)
[[1.284e+00-4.009e-17]
[-4.009e-174.908e-02]]
Если считать очень-очень маленькие числа (в степени -17) нулями, то ковариационная матрица нового трека
Python
1
2
[[1.2840]
[04.908e-02]]
стала диагональной! А это значит, что корреляция, а именно взаимозависимость между координатами x и y исчезла. Более того, малое значение корреляции для координаты y говорит о том, что мы имеем дело с шумом малой мощности. Сказанное влечет за собой важное следствие: теперь мы можем анализировать трек только по одной новой координате x, не обращая внимания на другую: она в силу ортогональности системы не оказывает никакого влияния.
Вернемся еще раз к собственным векторам. При программировании метода главных компонент, вычислительная сложность падает именно на алгоритм нахождения этих векторов. Это нужно учитывать при реализации, чтобы не получить проблемы с быстродействием системы.
Всем большой привет от дедушки Ляо!
Updated, или как все это было посчитано
Из комментариев стало ясно, что нужно заполнить пробелы этой статьи — более подробно рассказать, как были получены данные. Поэтому даю фрагмент псевдокода Python, из которого все должно быть ясно:
В пассивном радиолокаторе есть функция определения направления прихода сигнала DOA (Direct of Approach). Знание углового положения источника сигнала и помехи позволяет повысить однозначность определения координат цели на эллипсах равновероятного местоположения. В дополнение к уже рассмотренным адаптивным методам, попробуем реализовать нейроподобный подход к задаче определения DOA.
На вход нейроподобной сети (НПС) будем подавать сигнал с элементов кольцевой фазированной антенной решетки (ФАР); таким образом выход сети будет представлять собой гребенку пространственных фильтров. Или проще: каждый из выходов будет соответствовать одному из возможных направлений прихода сигнала; и на каком из выходов будем наблюдать больший уровень, значит пеленгуемый сигнал пришел с направления соответствующему номеру выхода.
Выход НПС, практически, формирует дискретную диаграмму направленности (ДН) ФАР.
Собираем нейроподобную ФАР
Для того, чтобы собрать рабочий тракт определения DOA с помощью нейроподобной сети, нам нужно определить следующие параметры сети:
представление, или образ входного сигнала ФАР (почему не сам сигнал? — об этом прочитаем дальше). Будем использовать 8 — элементную кольцевую антенную решетку и 8 представлений сигнала для каждого элемента; таким образом ФАР будет формировать 8 х 8 = 64 выхода для НПС;
соответственно, входной слой НПС будет содержать 64 элемента. Ограничимся точностью определения DOA в 1/16 от значений всех возможных направлений по азимуту, тогда выходной слой НПС будет содержать 16 элементов — выходов пространственного фильтра;
выберем в промежуточном, или как его еще называют, скрытом слое, значение элементов равным 32. Почему именно столько? Значение получено экспериментальным путем, приблизительный ответ на этот вопрос — потому что не много и не мало. Скрытых слоев у нас будет только один, поэтому наша нейроподобная структура будет содержать всего три слоя: входной, промежуточный (скрытый) и выходной.
Со слоями мы разобрались, теперь займемся собственно нейронами. В качестве таковых выберем сигмоид — элемент с передаточной функцией, представленной на картинке.
Передаточная функция нейрона. Выход всегда масштабируется в диапазон [0…1]
Выходной сигнал нейрона не превышает единицы, что обеспечивает снижение вероятности перегрузки сети. Нелинейная характеристика сигмоида гарантирует, что слабые сигналы, или шумы, не будут распространяться по сети, они будут подавляться более сильными сигналами. Точно также, сильные сигналы не будут вести к блокированию сети. Здесь не идет речь о какой-бы то не было линейной суперпозиции — все как в биологии, все преимущества — сильным сигналам: если уколол руку то сразу забываешь что у тебя чесалось в носу.
По формуле сигмоида наблюдательный сразу спросит, если нейроны продуцируют сигнал между 0 или 1, откуда на входе могут взяться отрицательные значения? Тут мы наконец должны вспомнить о самом главном в нейроподобной сети: о связях.
Непознаваемые связи
Посмотрим теперь, как будут связаны между собой нейроны нашей НПС. Поскольку сеть у нас простая, будем рассматривать только прямые связи, от нейронов входного слоя к нейронам скрытого слоя, и далее — от нейронов скрытого слоя к нейронам выходного слоя. Есть и другие структуры, в том числе с обратными свзями — они за пределами нашего повествования. Также мы должны упомянуть, что в приличной нейроподобной сети входной сигнал каждого нейрона образуется весовым суммированием сигналов N входящих связей с добавлением смещения b:
Каждый вес w определяет интенсивность связи; естественно что при w = 0 связь полагается отсутствующей. Смещение b определяет, в каком диапазоне входных значений будет работать нейрон, и значит — насколько существенными будут для него входные сигналы.
Это все замечательно, но что можно сказать о связях между нейронами? А ничего. Ничего мы про эти связи не знаем и более того — знать не собираемся. В таком случае, откуда они возьмутся? Другими словами, откуда нам брать значения wi и b для каждого нейрона?
Как и в живой природе, когда все организмы проходят адаптацию к своей среде, точно также мы будем развивать свою НПС. Мы будем ее учить, или тренировать. Мы будем показывать нашей сети образы различных сигналов и подсказывать ей, с какого направления они пришли. Чтобы отбор был более бескомпромиссным, мы будем эти сигналы зашумлять. При этом связи, которые оказались удачными, будут развиваться, а те которые были ошибочными — отмирать. В результате обучения формируется структура НПС со своими связями. Лучше даже и не пытаться анализировать эту структуру логически: она очень сложна и не поддается объяснению; она просто работает.
В результате, когда мы подадим на вход своей НПС тестовый сигнал, который даже никогда не присутствовал в обучающих последовательностях, на выходе получим направление его прихода.
Сигнал и светлый образ его
Выше я заметил, что буду использовать представление сигнала, или образ вместо самого сигнала. Признаюсь честно, вначале я пытался экспериментировать с самими сигналами, подавая их на вход НПС. Сеть никак не хотела сходиться к результату в процессе обучения. Вообще, отладка НПС — это кошмар, это настоящий черный ящик, в который никак не заглянуть.
В результате недолгих раздумий я пришел к следующим выводам. Нейрон — устройство сугубо нелинейное, и он будет существенным образом деформировать сам сигнал. Далее, предпочтительным для НПС, по аналогии с биологией, является визуальное представление данных (как это происходит например в глазу). Поэтому я поменял сигнал на его графическое представление, и все заработало. В данном случае каждый из восьми элементов ФАР апроксимировался вектором по аналогии с кодированием 8PSK. В результате, на входе нейронной сети каждый элемент ФАР представлен одним из восьми фазовых состояний.
Пора в школу
Теперь можно перейти к обучению нашей НПС. Моделирующая программа была написана на Питоне. Для каждого из 16 направлений прихода сигнала формировалось 10 обучающих выборок, которые отличались друг от друга шумовой составляющей. Для каждой обучающей выборки сеть проходила адаптацию по 30 циклам, или как это принято в терминологии НПС, по 30 эпохам.
После того, как НПС была сформирована, проводилось контрольное измерение облучением ФАР с направления 202,5° и обработкой сигнала ФАР нейроподобной сетью. Это направление соответствует 9-му выходу пространственного фильтра НПС. В результате получена диаграмма направленности:
Как видно из рисунка, НПС сформировала максимум в направлении 9-го выхода, что соответствует заданному углу.
В полярных координатах:
У вас есть желание взглянуть на то, какой получилась НПС? Пожалуйста, на диаграмме ниже она представлена во всей своей красе. Нижний слой нейронов — входной, в количестве 64. Выходной слой нейронов, соответствующих выходам пространственного фильтра, расположен сверху (16 нейронов). Промежуточный (скрытый) слой расположен посередине. По диаграмме, сигналы идут снизу вверх. Толщина связи зависит от веса связи: чем вес больше, тем толще линия. Наслаждайтесь и попробуйте выявить логику работы!
Нейроподобная сеть тракта обработки пассивного радиолокатора. Нижний ряд нейронов — входной, соответствует 64 представлениям сигнала 8-ми элементной ФАР. Выходной слой — 16 выходов пространственного фильтра. Кликните для увеличения
Назад, к природе
На этой характерной модели хорошо видно, что с точки зрения создания таких систем полученная структура не носит принципиального характера. Очевидно, что попытка ее декомпозиции или реинжиниринга не даст ничего для понимания заложенной логики. Вся логика — в алгоритме обучения.
Теперь вдвойне интересно, как это работает в творениях Природы. Опять таки очевидно, что бессмысленно анализировать связи нейронов и например сенсоров сетчатки глаза животных. Гораздо важнее ответ на вопрос, по какому обучающему алгоритму они были построены. И дальше — еще вопросы, вопросы без ответов:
происходит ли тренировка сети в процессе жизни одной особи или это результат долгой эволюции?
если это результат долгой эволюции, то как наследуется нейронная структура?
если тренировка сети происходит после рождения, не означает ли это, что стадии человеческого зародыша — личинки, рыбы, животного и так далее на самом деле есть алгоритм обучения нейронной сети?
на каких данных строится обучение в таком случае?
если деревья начнут расти горизонтально, будет ли меняться наша зрительная нейронная система?
не являются ли наши сны на самом деле обучающим видеоматериалом для нашей нейронной сети, в результате чего меняется ее структура?
В прикладном плане, НПС требует параллелизации обработки. Возможно, получат вторую жизнь технологии АВМ — аналоговых вычислительных машин. Каждую из таких АВМ, моделирующих нейрон, можно воспроизвести тысячами микро-ячеек. Самый сложный вопрос, для которого я пока не вижу технологии: как организовать произвольные настраиваемые связи между этими АВМ? Возможно, это можно будет сделать путем некоторого биолого — химического процесса.
Чем дольше думаешь об этом, тем больше завидуешь тому, как это сделала Природа.
Встречаются два программиста — один пишет на Си, другой на Ада. Си-программист говорит: — Я буду бифштекс с луком
Анекдот понятный только для тех программистов, кто в теме )
Отображение воздушной обстановки на экране диспетчера. Какое программное обеспечение скрыто за монитором?
Разработка программного обеспечения для промышленных систем становится более профессиональной. На рынке становится все меньше поделок под MS Windows, широко используются клиент — серверные решения. Unix — подобные операционные системы, такие как Linux, уже ни у кого не вызывают снисходительной усмешки. Военные заказчики также смирились с тем, что никаких бюджетов (в первую очередь американских) не хватит для собственной разработки базовых программных технологий, и скрепя сердце согласились с тем, что их придется брать с открытого коммерческого рынка — все то, что обозначается краткой абревиатурой COTS.
Модель разработки Open Source доказала свою жизнеспособность, и корпоративные программисты сейчас ломают головы, как использовать лакомые куски уже наработанного открытого кода и не нарушить условия лицензии GPL в своих разработках. Появился выбор инструментов и сред разработки, также появилось большое количество новых языков программирования. До этого в отечественной истории, в частности в разработке средств управления воздушным движением, принимали любые разработки — и на этом спасибо.
Новые времена — от победы любой ценой к надежности
Сейчас другие времена: рынок начинает насыщаться, и заказчики и программисты начинают задумываться о надежности и отказоустойчивости. Теперь нам интересно знать, что у нас с надежностью программного обеспечения в области автоматизированных систем управления воздушным движением? Думается, не нужно объяснять, как это важно для тех, кто находится на борту самолета, который сопровождает диспетчер. А сопровождение возможно лишь постольку, поскольку диспетчер видит всю воздушную обстановку, которую ему предоставляет софт КСА УВД.
Если мы хотим понять, насколько надежным является программное обеспечение КСА, возьмем для примера самую современную отечественную систему — КСА УВД Галактика. На сайте поставщика есть очень хорошие и важные разделы про подтвержденный уровень качества и безопасности, а также про надежность. Но там не хватает одной принципиальной строчки, которая есть у всех зарубежных разработчиков систем Air Traffic Control (ATC). И эта строчка даже не вишенка на торте, которая венчает серьезную и отказоустойчивую систему. Скорее всего, это весь торт и есть.
Но прежде чем мы возьмем лопаточку и начнем препарировать этот тортик, вернемся на много лет назад и попытаемся вспомнить, что мы знаем про язык программирования Ада.
ADA Language: восстание зомби
Вот и я вспоминаю, какие ассоциации вызвало у меня прочитанное про язык Ада. Вначале американскими военными (Departament of Defense — DOD) был разработан стандарт языка. Затем, уже на основе стандарта начали создаваться компиляторы и другие инструментальные средства. Для такого подхода есть даже специальный термин — опережающая стандартизация. И все это где-то затерялось в засекреченных недрах американских военных разработок. Вот такие первые ощущения; а первые — они самые сильные.
После этого я копнул чуть глубже. Фишка языка — встраиваемые системы и большие программные комплексы. Хорошо реализована многозадачность, и это уже интересно. И самое главное преимущество с точки зрения надежности работы программы — строгая типизация языка, которая не дает программисту делать ошибки, которые не обнаруживаются на начальной стадии компиляции и сборки проекта.
Ну хорошо. Мало ли какие прекрасные вещи можно заложить в стандарт, который останется пылиться на полке? Я помню модель протоколов и стандартов OSI, по которым планировалось строить сети во всем мире. Кто сейчас знает про стандарты ISO 8473 CLNP, ISO 9542 ES-IS, ISO 10589 IS-IS и ISO 10747 IDRP, которым предсказывали успешное будущее? Все они отправились в небытие когда появился TCP/IP, и этому протоколу никакие стандарты не предшествовали. Или может вы пользуетесь электронной почтой в соответствии со стандартом X.400, который был специально разработан для нее? Нет, повсеместно работает протокол SMTP, а про X.400 уже никто не вспоминает.
Мировое комьюнити программистов настороженно относится к руководящим документам, которые разрабатывают кабинетные академики, и на тот момент у меня сложилось впечатление, что язык Ада окончательно похоронили вместе с его стандартом. Чтобы в этом удостовериться, надо было копнуть еще немножечко и попробовать отыскать этот язык в виртуальных музеях безуспешных начинаний. Но, на мое удивление, в музее Ады не оказалось.
Зато я нашел этот язык там где уж точно не ожидал его обнаружить: в таких компаниях как Airbas, Boeing, Lockheed — Martin, Thales, Indra (вот эта последняя парочка работающая в ATC особенно интересна), а также в разнообразных критичных системах — начиная от парижских поездов метро, которые едут без машиниста, истребителях и заканчивая станциями, летящими к Марсу, а также ракетами Ariane, Atlas и Delta.
И вот тут стало по настоящему интересно. Где-то в самой что ни на есть профессиональной области элитного уровня существует затерянный мир языка Ада, о котором основная масса программистов, штурмующих PHP и Java в хорошо оплачиваемых web проектах ничего и не подозревает. Каким образом Ада ухитрилась вернуться из забвения и незаметно обосноваться в современности?
Задержка в развитии
Американские военные, породившие язык, все сделали как положено по уставу, то есть стандарту. Но на большее их не хватило: дальше пошли сплошные косяки. Во первых, они решили что весь софт для военных приложений будет крутиться на Аде, что оказалось совсем не так, но дело было сделано: от военных проектов было отброшено большое количество профессионалов, которые нашли себя в области свободных разработок, не завязанных на DOD.
Во вторых, барьер вхождения в эту область повысили еще раз, когда решили сделать лицензии на компилятор и другой инструментарий платными. Эти затраты уже точно стали неподъемными для обычных разработчиков, но вполне по силам крупным корпорациям, которые работают с военными. Для программистов на Ада стало гораздо меньше работы, чем для Си-программистов; и сейчас пожалуй самое время раскрыть смысл анекдота который вынесен в эпиграф. В этом анекдоте Ада программист заканчивает карьеру официантом, которому состоятельный Си-шник заказывает обед )
Эта бесхитростная логика потерпела сокрушительное поражение, когда выяснилось, что со временем круг людей которые разбираются в Ада исчезающе мал, зато те программисты которые получали возможность бесплатного профессионального роста на языке Си в области GNU/Linux, выросли и стали подавляющим большинством. Отсутствие людских ресурсов в Ада программировании привело к тому, что разработчики ПО для нового истребителя F-35 решили отказаться от Ада (на котором разрабатывался софт для F-22 и других самолетов) и начали разрабатывать его на языках C/C++. В результате проект начинает показывать все признаки провального — сложный комплекс ПО никак не удается отладить и запустить в полном объеме.
Со временем, наконец, до всех дошло, что нужно использовать бесплатные и открытые модели разработки, как это давно было сделано в Open Source, и появился свободно распространяемый проект GNAT, ничем по функционалу не отличающийся от лицензируемых инструментов Ада и который может использовать любой программист.
По опубликованным данным, в настоящий момент написано около 50 млн. строк исходного кода на Ада для систем вооружений, и большой объем ПО находится в текущей разработке. В 1996 году в США был произведен анализ рынка ресурсов разработчиков для Ада и Си. Всего было определено 1млн. 920 тысяч программистов, из которых 90.000, или менее 5%, писали на Аде.
ADA vs C
Теперь когда мы закончили с историей, перейдем к сравнительным цифрам, сопоставляя возможности Ада и наиболее популярного языка Си. Это сопоставление ни в коем случае не говорит о том, какой язык хороший или плохой. Они просто предназначены совершенно для разных применений.
Язык Ада можно сравнить с автомобилем, в котором приняты все меры безопасности: подушки, укрепляющие профили в дверях, автоматическая система стабилизации. В таком автомобиле вы будете защищены от неожиданностей, в нем можно возить всю семью и детей не опасаясь за последствия.
Язык Си — это натурально мотоцикл. Он дает вам кучу возможностей по сравнению с автомобилем. Вы можете проскакивать между рядами, газовать с места на высокой скорости и даже ездить по лестницам и заборам. Но это все вы делаете на свой страх и риск, и мотоцикл вам ничего не гарантирует: если что, даже шлем вам не поможет. Вы повезете своего ребенка на мотоцикле?
Кстати насчет шлема: среди менеджеров бытует мнение (к которому программисты, которые «в теме», относятся с большим скепсисом), что путем повышения «дисциплины программирования» и «качественного тестирования» можно убрать все ошибки из кода Си. Это жалкая попытка надеть шлем и при этом говорить, что мотоцикл теперь стал совершенно безопасным. Одной из отличительных особенностей Ады как раз является то, что это язык со строгой типизацией данных, что делает невозможными кучу ошибок, которые легко сделать на Си. И пусть вас не вводит в заблуждение, что программный комплекс работает целый год без сбоев: достаточно редкого сочетания данных и внешних условий, чтобы попасть на нетестированную ветку алгоритма (а все ветви протестировать невозможно), и вот тут дремлющая ошибка может сработать.
Но мы отвлеклись: возвращаемся к цифрам.
Вначале дадим информацию из Вики: по сравнению с Си программами, программы написанные на Ада содержат на 70% меньше исправлений и на 90% меньше багов. Большие преимущества Ада начинают проявляться при сопровождении сложных программных комплексов (а вы думали что самое главное это разработать софт? а вот и нет), где сопровождение «часто составляет около 80% от общей стоимости разработки».
Положим, Википедия не очень сильный авторитет. Обратимся к более весомым исследованиям, и поскольку мы плавно подбираемся к КСА УВД, таким авторитетом для нас будет FAA — Federal Aviation Administration, то есть американский аналог Росавиации, и известная компания IBM. В этой таблице приведены параметры надежного и безопасного программирования по данным FAA и IBM:
Наименование параметра
Ada 83
C
Availabilityм/ Reliability
Доступность / Надежность
21.5
11.6
Maintainability / Extensibility
Удобство сопровождения / Расширяемость
14.0
10.2
Приведем результаты еще одного любопытного исследования, в котором анализировались параметры проекта, в котором разработка начиналась на Си, затем также начал использоваться язык Ада, который на момент анализа составлял примерно половину проекта:
Наименование параметра
Ada 83
C
Количество строк исходного кода SLOC
1272771
1508695
Новые функции
23031
26483
Правки кода
5841
13890
Правки / новые функции
0.25
0.52
Правки / KSLOC
4.59
9.21
Стоимость разработки
$8.446.812
$15.873.508
Стоимость разработки / SLOC
$6.62
$10.52
Количество ошибок
122
1020
Количество ошибок / KSLOC
0.096
0.676
В таблице пересчитаны также относительные значения, приведенные к количеству строк исходного кода SCLOC. Мне представляется, что цифры говорят сами за себя: в проектах написанных на Ада меньше ошибок и они имеют более низкую стоимость разработки. Теперь, когда мы оценили потенциал этого языка, а также обнаружили, что он жив и очень хорошо используется в критичных системах, возникает вопрос: а что с этим в отечественной практике? Из чего состоит КСА УВД Галактика, которую мы выбрали в качестве примера?
КСА УВД Галактика: скучно и предсказуемо C++
Как я упомянул выше, признанные мэтры в области разработки средств управления воздушным движением — УВД (Air Traffic Control — ATC) Thales и Indra используют язык Ада. Теперь это уже далеко не секрет. Также не секрет и то, что все программное обеспечение КСА УВД Галактика написано на С++. Это обстоятельство нигде не афишируется, хотя зарубежные поставщики ATC свободно указывают тип используемого языка в своих материалах.
Как Си, так и его расширение C++ — замечательные языки. Однако они совершенно не подходят для разработки больших критичных систем, где возможно возникновение трудно обнаруживаемых ошибок.
Перейдем к конкретным примерам.
На примере ниже в результате механической ошибки программа Си будет работать совсем по другому алгоритму — не так как вы ожидали. Здесь показан участок кода, который обрабатывает и затем отображает трек воздушного судна и будет выполняться или нет в зависимости от переменной clear:
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// корректный Си код
if(the_signal==clear)
{
process_track(var1);
show_track(var2);
}
// механическая ошибка: вместо сравнения "==" указано присваивание "="
// тем не менее, это правильный с точки зрения компилятора код,
// и он будет выполнен, но с непредсказуемым результатом
if(the_signal=clear)
{
process_track(var1);
show_track(var2);
}
1
2
3
4
5
6
7
8
9
10
11
12
--корректныйАдакод
ifThe_Signal=Clear then
Process_Track(Var1);
Show_Track(Var2);
endif;
--еслидажесильнопостаратьсяиперепутать"="с":="
ifThe_Signal:=Clear then
Process_Track(Var1);
Show_Track(Var2);
endif;
--компиляторпокажетошибкуинескомпилируеткод!
В последнем случае компилятор Ада еще и ткнет вас носом, что вы именно перепутали:
Shell
1
2
3
$gnatmake uvd.adb
gcc-4.6-cuvd.adb
uvd.adb:27:15:"="should be":="
Си и не подумает вас ни о чем предупреждать. Не забывайте — это мотоцикл, он не ограничивает вас ни в чем, в том числе в таких милых погрешностях, в результате которых диспетчер не увидит метку на экране или увидит ее совсем в другом месте.
Я сам попадал на этот вариант, в результате тратил огромное количество времени, чтобы найти, в чем проблема. Но у меня были небольшие приложения и мне повезло что ошибка проявляла себя. Если же это большой проект КСА УВД и ошибка проявится только при определенных условиях? Например, если начнет работать алгоритм опасного сближения воздушных судов?
Другой пример. В Си точка с запятой — это пустой оператор, который просто не будет выполняться. Поэтому если вы влепите две точки запятой подряд (почистите клавиатуру от крошек!), ничего не будет. Но только не в том случае, когда этот пустой оператор окажется после if:
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// корректный Си код, лишняя точка с запятой после первой функции
// ничего не портит
if(the_signal==clear)
{
process_track(var1);;
show_track(var2);
}
// лишняя точка с запятой после оператора if:
// компилятор Си пропустит этот код, и две функции будут вызываться всегда,
// независимо от состояния переменной clear
if(the_signal=clear);
{
process_track(var1);
show_track(var2);
}
Для такой ошибки в Си программе КСА УВД диспетчер увидит кучу треков, в том числе ложных, которые на экране появляться не должны.
И в этом случае, компилятор Ада не только укажет на синтаксическую ошибку, но и покажет что точка с запятой избыточна и не на своем месте:
Shell
1
2
3
4
$gnatmake uvd.adb
gcc-4.6-cuvd.adb
uvd.adb:26:21:extra";"ignored
gnatmake:"uvd.adb"compilation error
Вы знаете, пока я тестировал эти примеры на своем компе, мне начал нравиться этот язык. Больше всего мне понравилось то, что он имеет встроенные средства многозадачности, чего нет даже в Си. Про многозадачность я напишу в следующий раз, а здесь приведу еще один пример, каких типовых ошибок программирования удается избежать за счет строгой типизации языка Ада. Это очень, очень опасная и распространенная ошибка, которую Си никак не контролирует — выход за границы массива. Если вы просчитались с оценкой размера массива, или совершили ошибку в вычислении индекса, или неправильно организовали цикл… причин может быть множество; в результате вы забираетесь в области памяти, которые принадлежат другим переменным, и эффект опять таки будет непредсказуем.
И полбеды, что это будет именно «эффект», то есть вы будете его наблюдать. Наблюдаете — значит знаете об ошибке. Гораздо хуже, если эффекта не будет, и он проявит себя когда КСА УВД уже в эксплуатации, наступает сочетание нетестируемых факторов…
Ниже программа на Си, которую я также протестировал на своем компе. Она корректна с синтаксической точки зрения, компилятор обрабатывает ее молча, но в ней есть существенный изъян: из-за логической ошибки во втором цикле мы вышли за пределы объявленного массива b и записываем в память уже не значения b, а непонятно что. Никто не схватит нас за руку и не предупредит об этом!
C
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <stdio.h>
inta[5];
intb[5];
intmain()
{
inti;
// заполняем массив a
for(i=0;i<5;i++)
a[i]=i;
#if 1
// внимание - мы промахнулись с границами массива b!
for(i=5;i<10;i++)
// массив b не получит свои значения
b[i]=-2*i;
#endif
// выводим значения массива a - он испорчен
for(i=0;i<5;i++)
printf("[%d] a=%d\n",i,a[i]);
}
Молчание компилятора и результат работы программы:
Shell
1
2
3
4
5
6
7
$gcc-ouvd uvd.c
$./uvd
[0]a=-16
[1]a=-18
[2]a=2
[3]a=3
[4]a=4
Тадам! Что случилось с нашим массивом a? Точнее, с его первыми двумя элементами? Они затерты вторым циклом. Такой цикл мог располагаться вообще не в нашей программе, или в другом файле, или быть написан позже другим программистом. Сколько дремлющих ошибок в Си коде ждут своего часа, чтобы выйти наружу?
Мотоциклу все равно — если решили сделать крутой разворот и выпали из седла — ваши проблемы. Только посадите ли вы своих детей в такой мотоцикл? И как быть с пассажирами на воздушном судне?
Ошибочка вышла! Ада обнаружила что индекс в цикле вышел за границы диапазона. Вот она, прелесть строгой типизации.
Повторюсь, что Си — это прекрасный язык. Но по изложенным причинам совершенно не подходит для критичных приложений, какими являются средства управления воздушным движением (позже я коснусь расширения C++ — все изложенное справедливо и для него, и есть еще дополнительные проблемы). Широко известен набор оправданий, когда выбор несоответствующего инструмента пытаются подменить тем, что «мы будем работать с этим безопасно». Например, оденем шлем на мотоцикле. Или будем забивать гвозди вместо молотка топором, а в инструкции напишем что забивать нужно тыльной частью, а не острым концом, и обяжем всех внимательно следить чтобы острием не заехать себе в глаз.
Когда больше нечего сказать: пришло время оправданий
Итак, послушаем менеджеров, пиарщиков и всех тех, кто продвигает продукты на рынок АС УВД. Вам показалось, что мы забыли программистов? Совсем нет. Это только в менеджерской среде бытуют иллюзии, что качество кода можно поправить инструкциями, внедрением чего-либо типа ISO 9000 или SAP. Поговорите с программистами в курилке: вы обнаружите, что они испытывают такую веселую уверенность в том, что в написанном ими коде наверняка приличное количество ошибок, которые еще ждут своего тестировщика. И это будет наше первое оправдание —
Оправдание №1. Программисты не должны ошибаться
Люди всегда ошибаются. Можно только минимизировать степень этих ошибок. Помните предыдущие таблицы? Это сухая, безразличная статистика. Язык Си развязывает руки и многие вещи считает не «багами», а вашими «фичами». Язык Ада требует от вас ясно выразить то, что вы хотите.
Еще раз: сухая статистика о количестве обнаруженных ошибок на каждую тысячу строк кода:
Количество ошибок / KSLOC
Ада: 0.096
Си: 0.676
Будьте уверены в том, что в такой же примерно пропорции в вашем проекте есть необнаруженные ошибки. Со статистикой бесполезно спорить, ее можно только учитывать.
Оправдание №2. Все ошибки можно обнаружить тщательным тестированием
Дружный хохот программистов в курилке. Для начала, простой вопрос: есть ли в штате разработчиков КСА УВД «Галактика» отделенные от программистов тестеры, какая статистика в багзилле (а есть ли она вообще, система учета tickets?), сколько в премии теряют кодеры на каждую обнаруженную тестером ошибку, сколько в премии теряют тестеры на каждую ошибку, обнаруженную саппортом (а есть ли она в компании вообще, служба поддержки?) После этого можно поговорить про «тщательное тестирование». Кстати, что про это говорит ISO 9000?
Оправдание №3. От выбора языка ничего не зависит. Все решает комплекс мер и правильная архитектура
Это оправдание уже более компетентных людей. Теперь встречный вопрос: как вы собираетесь выстраивать правильную архитектуру на основе Си кода с сотнями заголовочных header файлов? Или может лучше строить архитектуру на языке Ада, который как раз предназначен для больших проектов с миллионами (!) строк кода?
Повторно обращаем внимание на изложенные выше примеры: у вас правильная архитектура основанная на Си коде, а ошибка в одном модуле убивает переменные в другом, хе-хе. На этом вся архитектура заканчивается.
Оправдание №4. Проблемы надежности ПО решаются аппаратным резервированием
То, что аппаратное резервирование серверов решает проблему надежности ПО — иллюзия специалистов которые никогда не писали программ. Если программный сбой возник в основном комплекте сервера, с высокой вероятностью он повторится и в комплекте, который находится в горячем резерве.
Эта особенность была хорошо известна разработчикам VCS Shmid Telecom, которые посвятили этой проблеме значительное время во время общения с нами в офисе компании в Цюрихе. Были разработаны специальные меры для того, чтобы потенциальная программная ошибка не была воспроизведена и при резервировании. С КСА УВД все еще сложнее: нужно сохранить предысторию состояния системы, т.е. все треки и местоположения воздушных судов, которые имели место быть до сбоя.
Оправдание №5. Мы начинали проект уже давно на Си и у нас нет возможности переходить на Ада сейчас
Честный ответ. На языке бизнеса это означает: мы вложили свои деньги в дело и заработаем на своих инвестициях; и неважно, надежный этот код или нет. Желающие могут ознакомиться с нашими сертификатами и актами, которые подписал заказчик. Поскольку это оправдание административного уровня, тут и возразить нечего.
Немного про C++
КСА УВД Галактика написана на C++, поэтому уделим этому расширению языка Си немного внимания. C++ это язык который реализует концепцию объектно — ориентированного программирования. В нем исползуется изоляция реализации методов класса, позволяя сохранить стабильные интерфейсы. Однако защищенность приватных членов класса от изменения снаружи работает только на логическом уровне. На физическом уровне объекты класса точно также располагаются в памяти, как и массивы в примерах которые я привел выше, и они точно также могут подвергнуться изменению.
Кроме этого, у C++ есть серьезные критики. Очень трудно обойти мнение Линуса Торвальдса, автора операционной системы Linux (которая вся написана на чистом Си, без использования С++: интересно почему?), который так высказался об этом языке (выражения похожие на ненормативную лексику смягчены
Это на самом деле так, поскольку все классы в C++ наследуются от самого высокого уровня абстрактных классов, и выбор структуры этих классов очень важен, поскольку под ними со временем возникает целая иерархия и изменить что-либо на верхнем уровне уже невозможно. Как правило, представления о структуре данных и методов в начале проекта и то, к чему мы приходим в конце проекта, существенно разнятся. На это нам и указывает Линус, и к его мнению стоит прислушаться: как никак, ядро Линукс это огромный проект, и кому как не ему знать, как строится архитектура таких проектов.
Еще одно замечание системного уровня. Этот уровень для нас очень важен, поскольку одну программу может написать любой, а комплекс требует совсем других компетенций и опыта:
Тоже очень интересная мысль. Значит, начиная в C++ мы постепенно выбрасываем из него вещи, которые мешают быть нашему проекту быть переносимым и эффективным, и в результате приходим к тому, что используем функционал языка Си. И больше никаких классов.
Кстати, замечание: модель объектно — ориентированного программирования не тождественна классам. Ее можно реализовать и на Си.
В этих словах Линуса можно предсказать судьбу C++ проекта КСА УВД Галактика: со временем рамки абстрактных классов верхнего уровня станут тесными, и софт ждет переработка на уровень вниз — до языка Си. Если к этому времени он не будет портирован на Ада.
Послесловие
Вот и подошло к концу наше небольшое исследование. Почему мы обратили внимание именно на КСА УВД Галактика? Причина в том, что другие поставщики систем УВД не позиционировали свои продукты как современные, передовые и соответствующими правилам Евроконтроля. А поскольку для Галактики написано что она современная, нам захотелось больше узнать про лучшие отечественные примеры.
Вернемся еще раз к тому, что написано на сайте поставщика Галактики про качество и безопасность. Там есть «вишенки» про «соответствие международным стандартам ED 153, DO278/ED 109 (SWAL 3 and 4)», но нет «тортика»: «ПО разработано на языке Ада». Поэтому вишенка как-бы повисает в воздухе: как можно обеспечить соответствие указанным стандартнам безопасности разрабатывая программы на Си?
Известные компании Thales и Indra указывают, что разработка средств УВД ведется на языке Ада. Это точно торт который нужен; к нему не стыдно присовокупить вишенку про то, что надежность ПО в соответствии с требованиями DO278/ED 109 обеспечена.
Когда я после института пришел работать в контору, она была всего лишь филиалом именитого НИИ измерительной техники г. Челябинск — НИИИТ. Кто работал в почтовых ящиках в советскую пору, знает что все эти названия ничего общего с действительностью не имели. «Промышленная автоматизация» означала разработку средств ПВО, «среднее машиностроение» — создание ядерного оружия, вагонзаводы делали танки. Вот и НИИИТ специализировался на радиолокации, радиопеленгации и системах посадки.
Какая тематика может быть у филиала? Естественно, ему сливают второстепенные узлы, которыми заниматься недосуг. Самые вкусные куски метрополия всегда оставляет себе. Так бы и случилось, если бы не амбиции руководства филиала и потенциал многочисленных челябинских специалистов, которые решили покинуть насиженные места в НИИИТ и рискнуть начать с нуля в филиале в Махачкале. Совместными усилиями филиалу удалось получить огромный заказ — разработку унифицированного ряда радиопеленгаторов «Пихта». Поскольку история происходила в середине 80-х годов, можно получить представление об элементной базе тех времен: от аналоговой обработки уже начали уходить, но микропроцессоры использовать еще не начали. Весь радиопеленгатор состоял из микросхем логики 133 серии. Руководители проекта пошли по пути наименьшего риска: пусть объем аппаратуры будет огромным, но зато с предсказуемым результатом.
PDP vs Intel
На нас, молодых инженеров, предсказуемость результатов впечатления не производила. Уже начали появляться процессоры серии 1806 с прекрасной PDP-системой команд и цельнотянутый К580 с ужасной организацией внутренних регистров. В конторе быстро возникло два полуподпольных направления, которые активно разрабатывали микропроцессорную тематику — фанаты PDP и сторонники Intel 8080.
Сейчас Intel выглядит признанной иконой, но в то время был совсем не факт, что он станет лидером. Был еще один сильный игрок — Motorola со своим процессором 6800, и он был настолько популярен, что в классической книге Титце и Шенка «Полупроводниковая схемотехника» именно микропроцессор Motorola 6800 представлял главу по микропроцессорной технике.
Я и сейчас считаю, что система команд PDP была непревзойденной. Когда можно использовать любой регистр в операции, включая даже счетчик команд и указатель стека — это давало невероятную гибкость. Восьмеричные листинги кода мы читали не заглядывая в справочник. На этом фоне разрешить класть результат операции только в один регистр, именуемый аккумулятором, как это было сделано в Intel, выглядело уродством.
Разработка вопреки
Если вы считаете, что руководство поощряло наши процессорные изыскания, то глубоко заблуждаетесь. Несмотря на то, что всем этим мы занимались вечером, во внерабочее время (вот были же энтузиасты!), начальники, обнаружив нас, устраивали выволочку. Нравы конторы что тогда, что сейчас, не очень сильно поменялись. Но, как говорится, под давлением мы становимся сильнее. Жажда знаний и самостоятельности сыграли свою роль. В результате подпольных изысканий вызрела концепция микропроцессорного радиопеленгатора, и вслед за концепцией последовало воплощение в виде работающего макета. Точнее, это был процессорный тракт обработки сигнала, который начинался сразу с выхода приемника. Приемники в отечественных РП всегда были покупными, а сделать новую антенну в подпольных условиях у нас не получилось бы (это не помешало нам заниматься разработкой вибраторов).
К этом времени и весьма кстати подоспели инструменты. Среди них — вычислительный комплекс ДВК-3, который стал ядром макета. С комплексом шла подробная документация, включающая электрические принципиальные схемы, и операционная система с макроассемблером, редактором и другими утилитами, которые располагались на дискете 360К (внимание, это килобайты!).
Макет радиопеленгатора на ДВК
Наш макет имел следующую структуру. Сигнал с выхода приемника проходил через согласованный фильтр, после фильтра стоял фазовый детектор. Все это располагалось на одной плате, которая врубалась в корзину шины ДВК. Кстати, используемая Q-шина имела еще один приятный нюанс: если устройство на шине не отвечало процессору на обращение по его адресу сигналом PRLY, процессор генерировал прерывание по вектору 10. И опять таки, в интеловской конфигурации было так странно привыкать к тому, что можно читать данные по несуществующему адресу и это пройдет незаметно.
Контроллер врубной платы при поступлении фазовых данных захватывал шину, заполнял память в режиме ПДП и формировал прерывание. Далее в дело вступал софт. Все программы были написаны на ассемблере; естественно никакой плавающей точки не было. Уже тогда в коде мы преодолели многие проблемные точки разрабатываемой Пихты. Результат пеленгования выводился прямо на экран ДВК.
Помимо обработки, мы сделали плату управления сканированием антенной системы. Все это заканчивалось разъемами точно такими же, как и у создаваемого образца РП «Пихта» — мы ждали удобного момента для подключения к приемнику и антенне, а второй такой возможности могло и не представиться. И тут перед нами распахнулось окно возможностей, связанных с судовым радиопеленгатором…
Море, ты слышишь, море…
Морское направление открылось у нас по заказу Ленинградского КБ «Связьморпроект». Эту разработку «подстегнули» к унифицированному ряду «Пихта», поскольку планировалось использовать модули этого РП. ОКР назвали «Пихта-2С» и в ее результате должен был появиться радиопеленгатор диапазона 100 — 180 МГц для морских судов и буровых платформ. Поскольку приспособить узлы с жесткой логикой к новому изделию не так просто и быстро, работа шла ни шатко ни валко. Направлением занимался соседний сектор, и в конце концов они арендовали судно, установили на нем антенну и собрались провести испытания своего блока. И тут пробил наш звездный час.
Благодаря инсайдерам в соседнем секторе, мы узнали время проведения испытаний и заявились на судно со своим оборудованием — ДВК, платы и так далее. Это больше походило на пиратский захват, которому весьма способствовала пассивность начальника этого сектора — он был совершенно равнодушен к тому, что происходило. Судно вышло в море, мы подождали когда коллеги отработают свою программу и затем с нетерпением отсоединили чужие блоки и подключили свои к антенне и приемнику. Выходит на связь береговая радиостанция, и о — чудо! — на экране ДВК появляется правильный пеленг. Победа!
Параллельно с испытаниями мы записывали на диск несущий сигнал с антенны, это потом пригодилось для работы с фазовыми искажениями. Мы крутили судно во всем диапазоне азимутов, чтобы определить, как влияют его надстройки на фазовый раскрыв. Наша настойчивость была вознаграждена, и домой нас вообще не тянуло — мы заночевали прямо на палубе, под открытым небом. В кубрики спускаться никому не хотелось. Перед сном вместе с командой на палубе мы зарядили здоровую коладу, после чего утром мы были вознаграждены хорошим уловом из нескольких осетров. После того как судовой кок начал разбираться с осетринкой на камбузе, соблазнительный запах быстро поднял всех со своих спальных мест. После волшебного завтрака на море работа была продолжена.
Все впервые
После этого начальству не оставалось больше ничего, как просто смириться с происходящим (победителей не судят). Тематику передали в наш сектор, а меня назначили главным конструктором судового радиопеленгатора. После того, как был отработан макет, началась разработка опытного образца.
В моей радиопеленгационной истории есть два принципиальных перехода. Второй был, когда я вернулся в контору для того, чтобы разработать РП «Платан». А первый — когда мы делали именно этот радиопеленгатор — Пихта-2С. Эти два изделия можно сравнивать по тому, какое количество новых технологий было использовано одномоментно.
Итак, перечисление того, что было реализовано в Пихте-2С со словом «впервые»:
впервые в отечественной практике использован микропроцессор для обработки сигнала и управления, в отличие от жесткой логики;
впервые разработан специализированный пеленгационный радиоприемник, до этого во всех отечественных РП использовался покупной связной радиоприемник;
впервые использованы многочисленные возможности, которые дает разработка с использованием программного обеспечения: электронная юстировка антенны, введение калибровки антенны по диапазону, псевдо — многоканальный режим с одним приемником, устойчивый алгоритм фазового детектирования, невосприимчивый к большим девиациям фазы и многое другое.
На этом фоне другие достижения выглядят уже не так впечатляюще, хотя это тоже значимые результаты:
разработан удлиненный вибратор на диапазон 100 — 180 МГц, устойчивый к судовым КВ полям напряженностью до 100 В/м ;
обеспечено качественное прослушивание пеленгуемого радиообмена по опорному радиоканалу, в отличие от прослушивания в предыдущих РП на фоне модуляции антенной системы;
конструктивно весь пеленгатор вместе с приемником упакован в один блок, в котором также располагается индикатор пеленга и клавиатура;
тракт радиоприема и обработки невосприимчив к ЧМ модуляции, которая используется в судовой связи. Для РП «Пихта» ЧМ ведет к развалу фазовой огибающей и отсутствию пеленгования;
радиопеленгатор адаптирован для пеленгования вертолетов, для которых характерен эффект паразитной АМ/ФМ модуляции сигнала, вызванной вращением лопастей винта вертолета;
автоматическая система контроля позволяет определить отказавший узел. Сейчас это выглядит очевидным, но в РП того времени такого функционала не было.
Покой флибустьеров
Команда РП «Пихта-2С». За антенной ее ведущий разработчик — Семен Ханцис, продолжает заниматься любимым делом только уже в другой стране -Don’t worry, be happy! Слева от меня — мой первый зам Александр Дзюба. Блок пеленгатора и антенна ждут погрузки на судно на очередные испытания
Возможности, которые предоставляла программная реализация, позволили исследовать и реализовать новые алгоритмы обработки сигнала. Они и были базовыми программными технологиями, получившими развитие в РП «Платан».
Блок Пихты-2С на фоне антенны, установленной на палубе судна. Съемка на причале в порту
Вся моя деятельность в рамках проекта «Пихта-2С» получила свое логическое завершение в кандидатской диссертации на тему «Оптимизация и пути реализации цифровой обработки сигналов в морских фазовых УКВ радиопеленгаторах». Диссертацию я защищал в Ленинграде, в ЛВИМУ им. адмирала С.О.Макарова, а диплом получал уже в Санкт-Петербурге, в Государственной Морской Академии — это была эпоха переименований и перемен.
Еще один штрих к коллективному портрету руководства конторы: когда из Питера пришло приглашение на вступительные экзамены в заочную аспирантуру, поехать мне не дали. Я не стал конфликтовать (хотя по законодательству имел полное право на учебный отпуск для вступительных экзаменов) и, потеряв год, взял обычный отпуск для повторного поступления. И тут, прознав про то что я собрался в Питер, контора пыталась мешать как могла, вплоть до угрозы увольнения. Вот так понимаешь и двигали прогресс — вечерами, тайком работали и тайком учились в аспирантуре.
Радиопеленгатор «Пихта-2С» стал поводом гордости для конторы и показателем ее технологических достижений. Продолжая это направление, я сделал еще один проект — встраиваемый РП для радиолокационного комплекса «Комар-2» Tesla Pardubice. В ходе этого проекта договорились с чешскими коллегами использовать образец «Пихты-2С» в аэропорту города Hradec Kralove. Там как раз наши военные покидали аэродром, и его перепрофилировали под гражданские нужды. Такими возможностями для промо своих изделий не пренебрегают, но и тут контора проявила свой норов: пеленгатор под демонстрационные цели в чешский аэропорт не отдадим, пусть покупают за 80 тыс. долларов. Естественно, после такой суммы разговор был завершен.
Приемный тракт РП, разработанный для Пихты-2С, контора так и не смогла воспроизвести. Сказалась потеря специалистов в лихие 90-е годы. Радиоприемник и радиостанцию для АРП «Платан» разрабатывала зеленоградская компания НЭЛС. Впрочем, к нынешним временам стиль торгово — закупочного кооператива в разработке вполне утвердился: очень выгодно выкупать продукт у малых компаний, не имеющих доступ к рынку, и продавать своему постоянному заказчику.
Секреты новой антенной системы Пихты-2С. Восьмиканальный коммутатор, генератор контроля антенны и все. Однополосного модулятора больше нет, с антенны идет два кабеля — канал кольцевого и центрального вибратора.

 = \sum_{t}\,s(t + \tau)\, r^*(t)\,e^{j2\pi ft}")
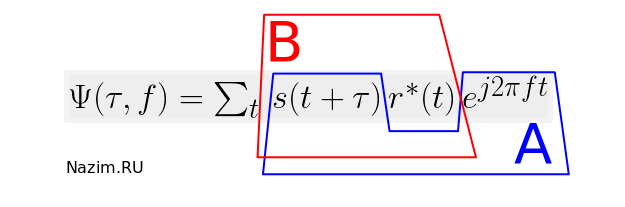


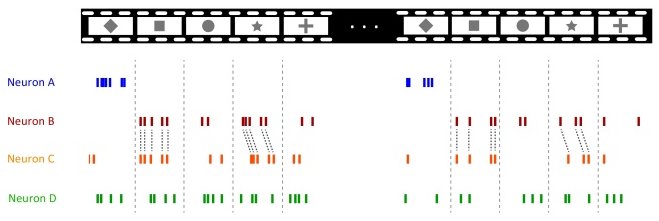


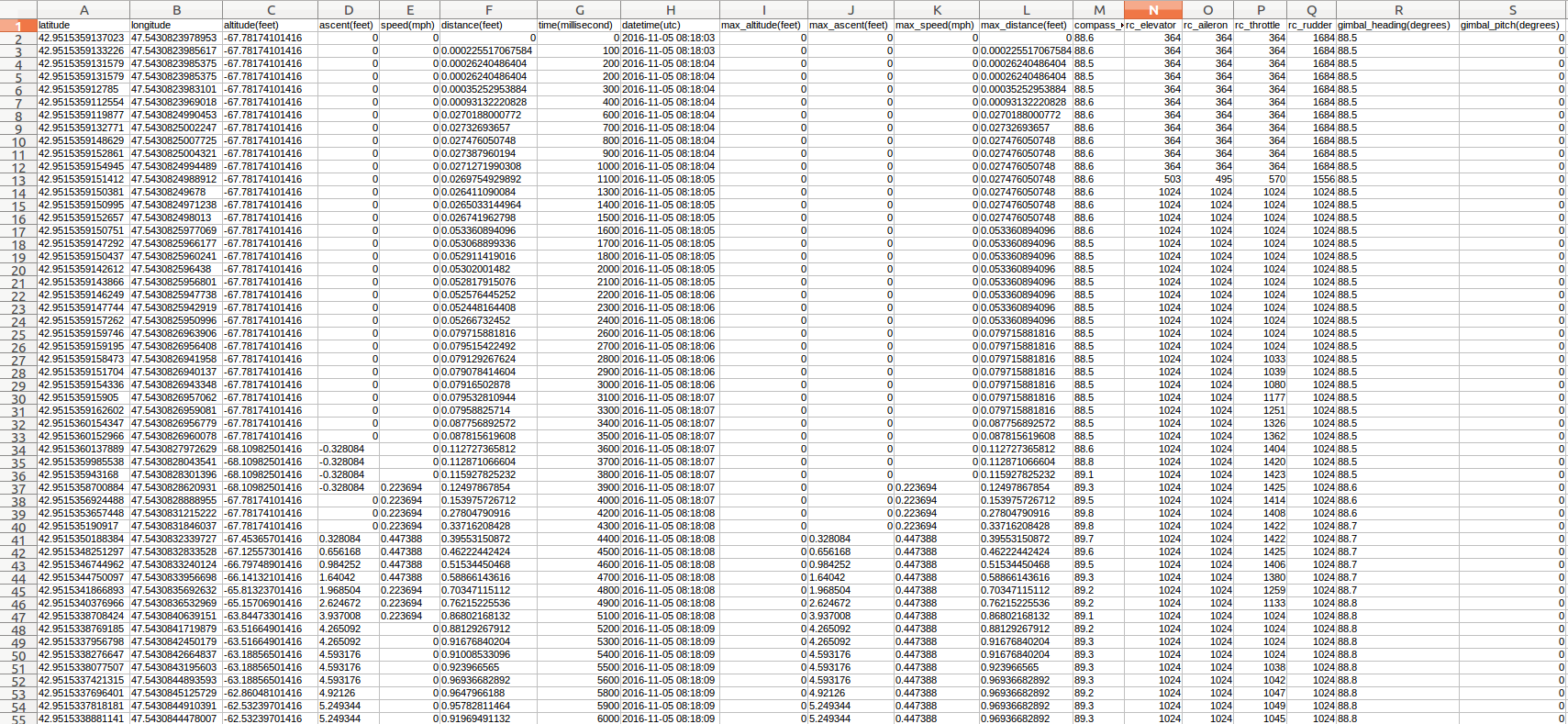
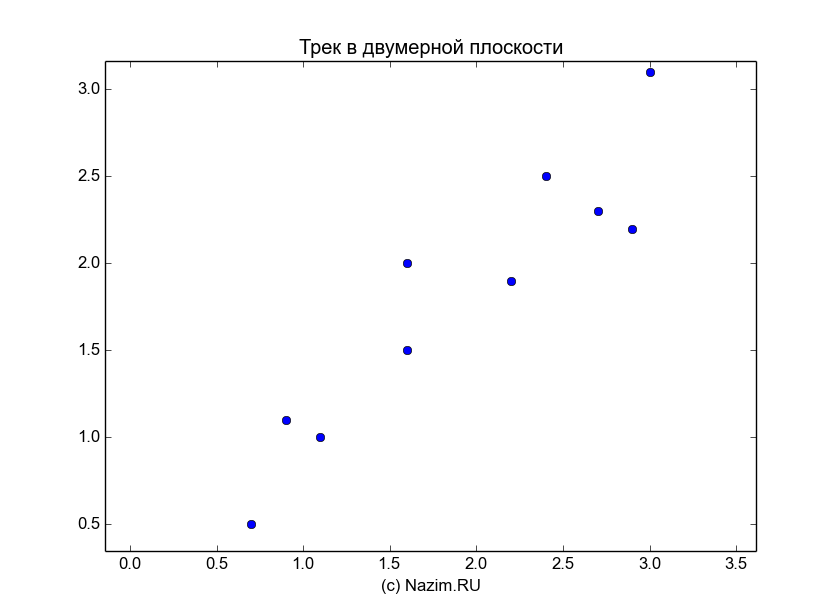
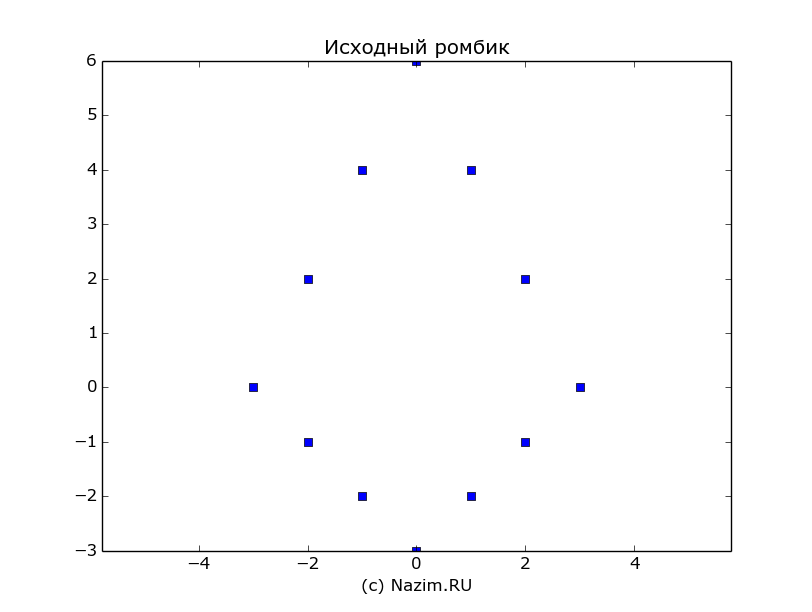
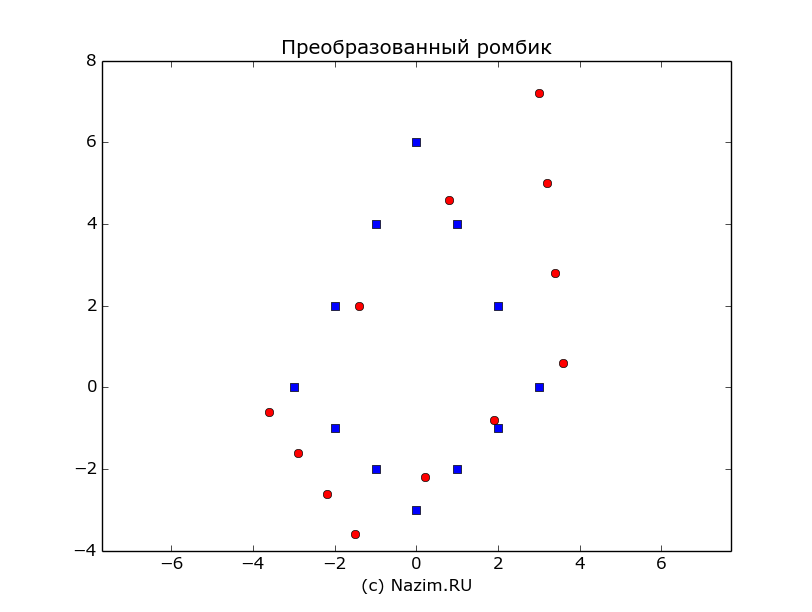
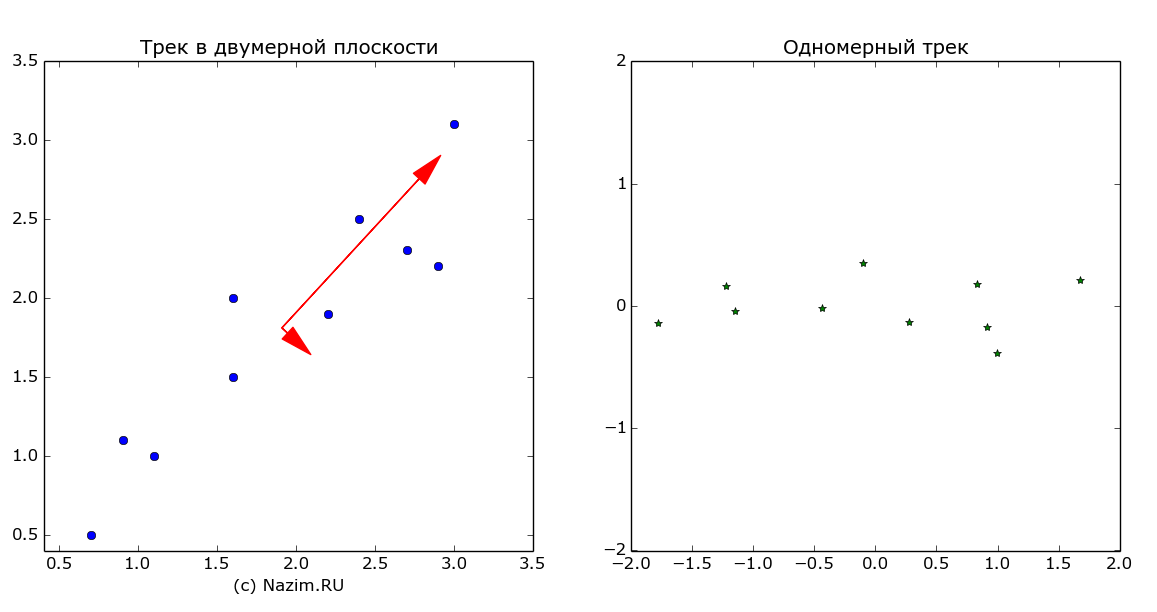
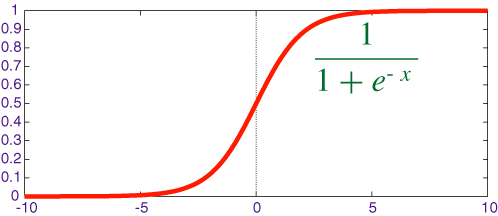

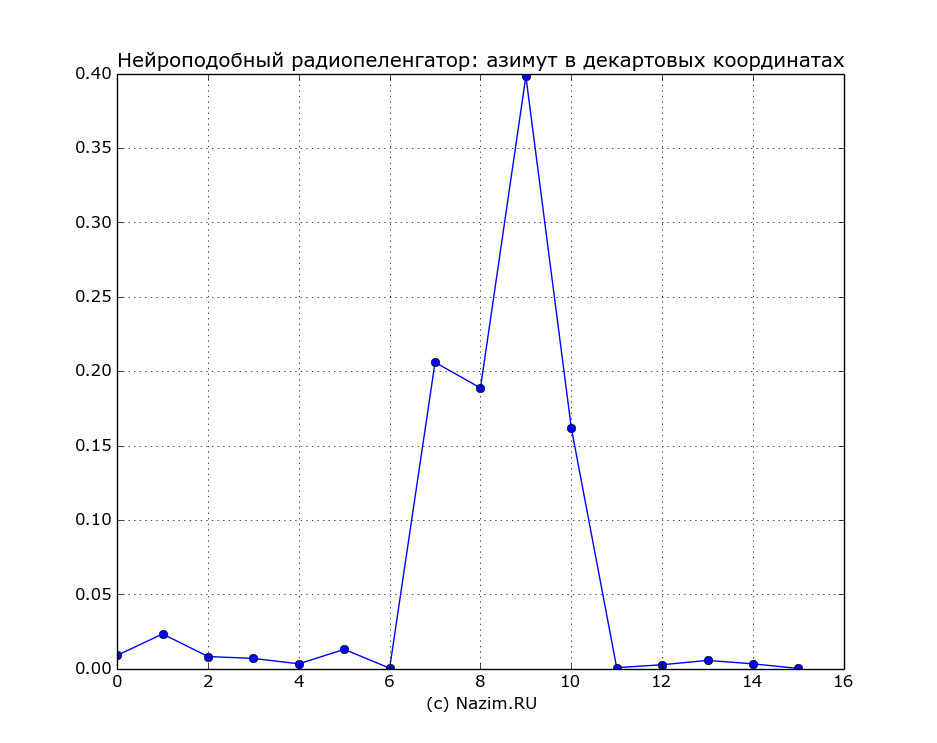
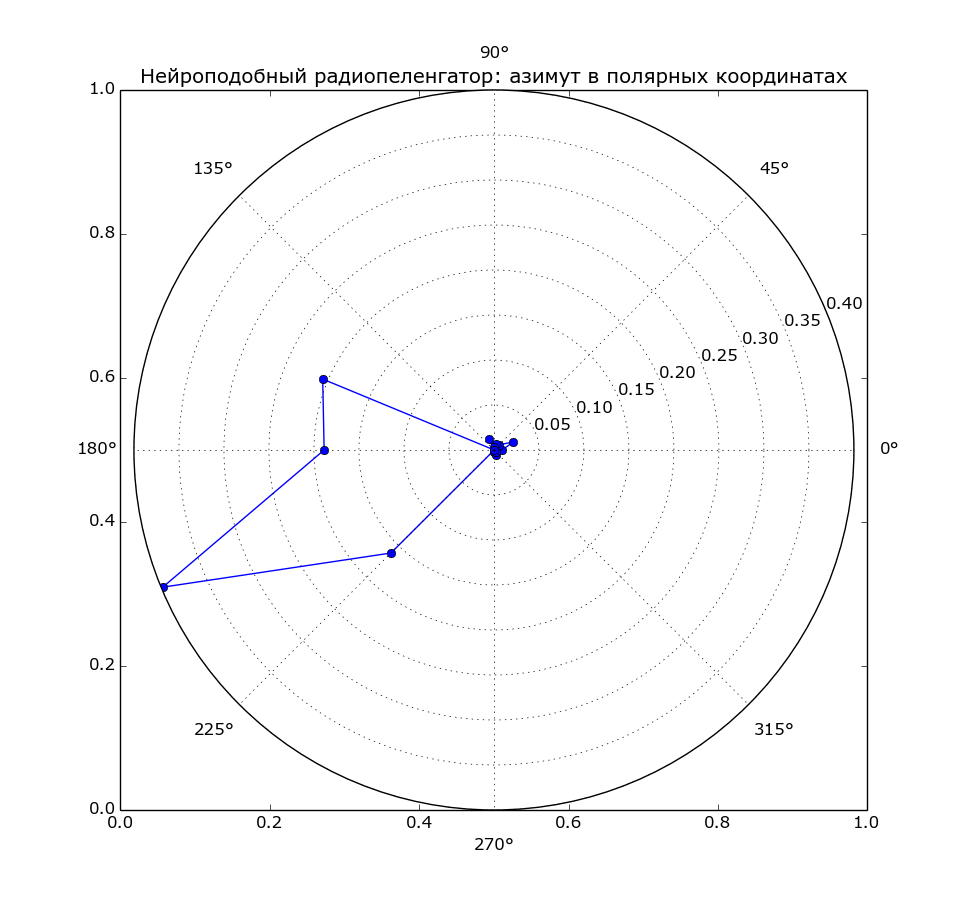
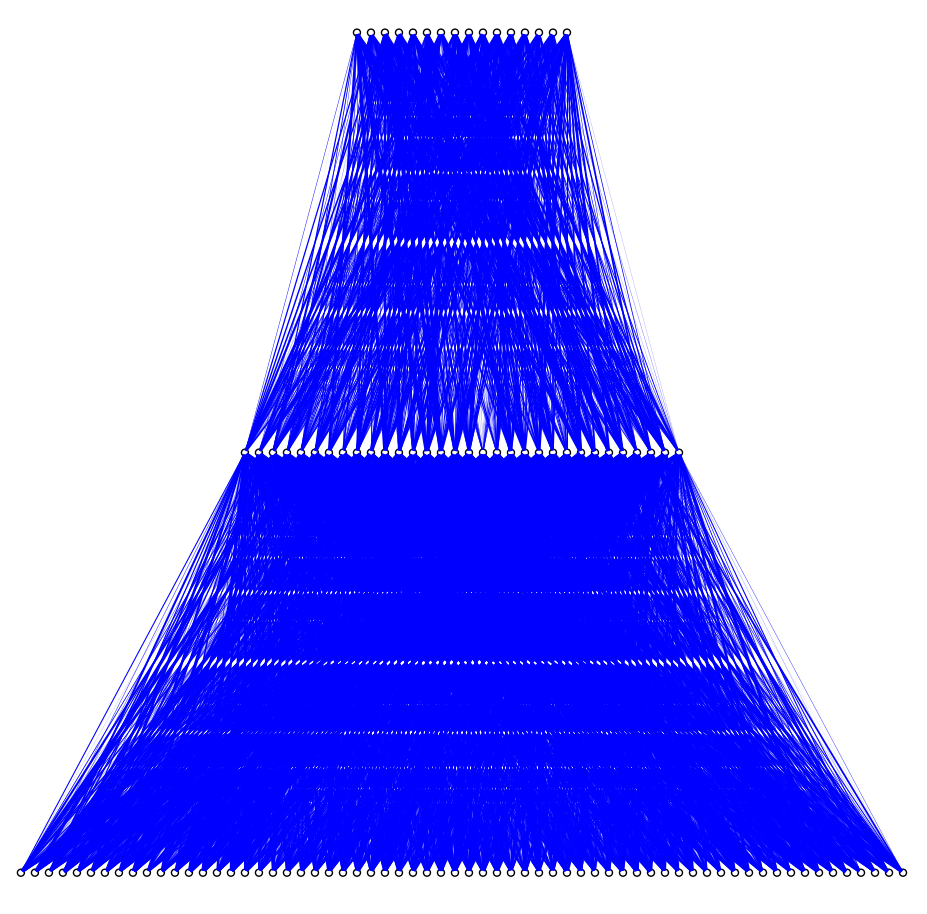




Last comments